当前位置:网站首页>3、多智能体强化学习
3、多智能体强化学习
2022-07-07 23:21:00 【C--G】
基本概念
Settings

- Fully Cooperative Setting


- Fully Competitive Setting


- Mixed Cooperative & Competitive

- Self-Interested Setting

基本术语
State,Action,State Transition

Rewards
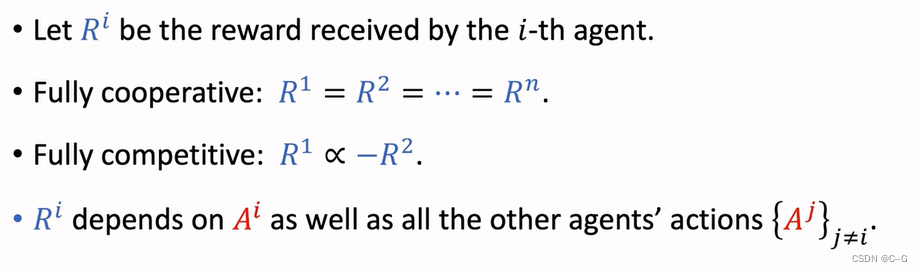
Returns

Policy Network

Uncertainty in the Return

State-Value Function


Convergence
- Single-Agent Policy Learning

- Multi-Agent Policy Learning

- Difficulty of MARL
Single-Agent Policy Gradient for MARL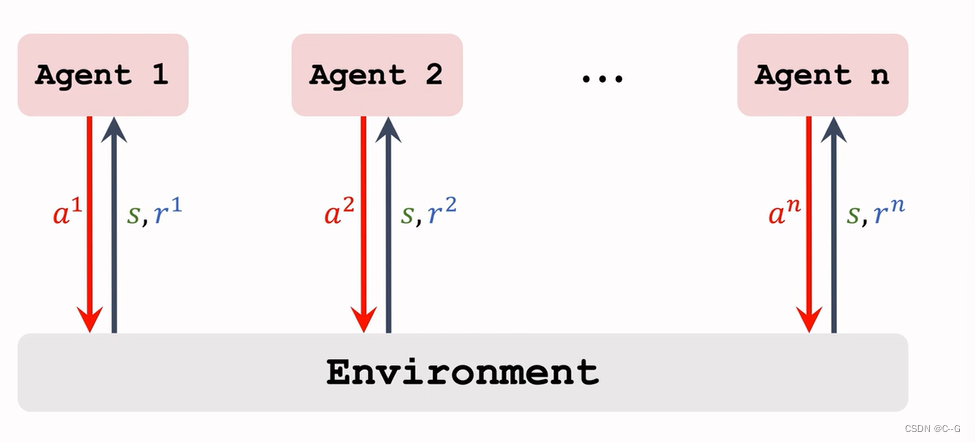



Architectures


Fully Decentralized
- Execution
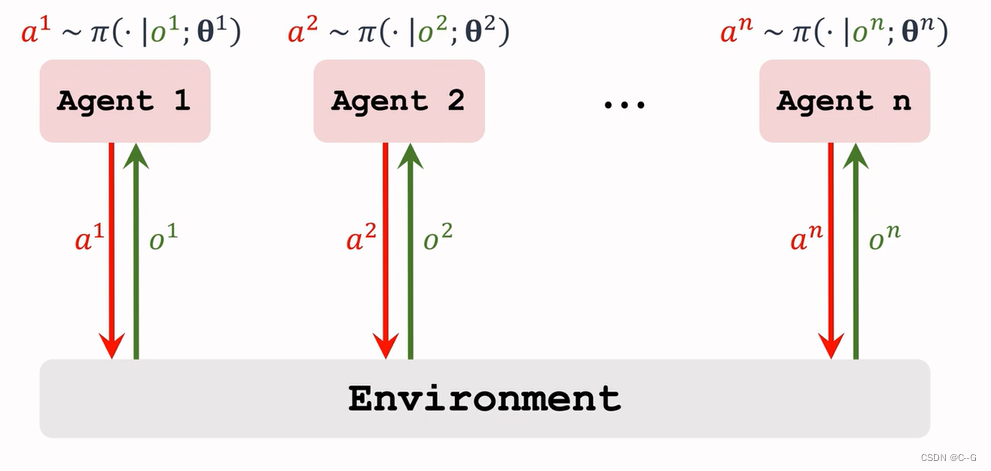
- Actor-Critic Method

Fully Centralized
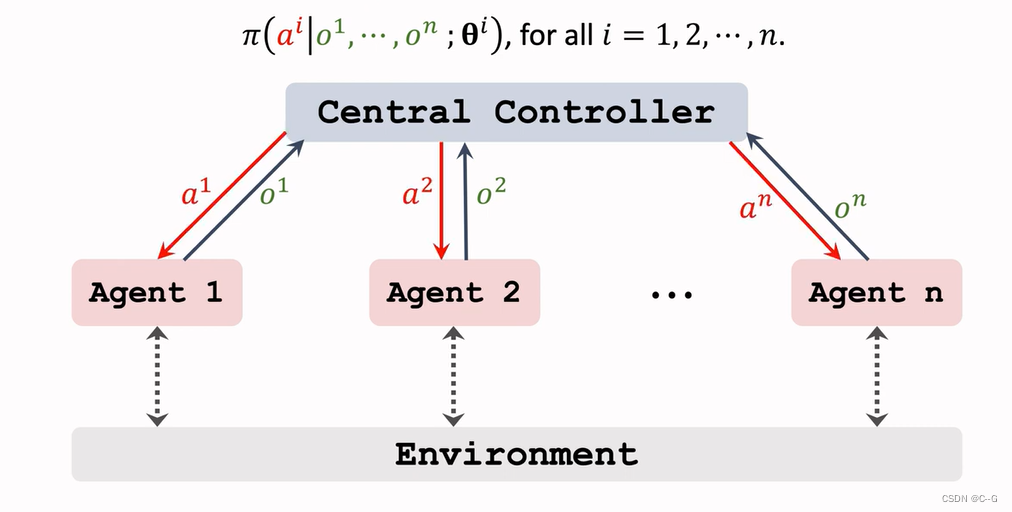
- Method


- Shortcoming:Slow during Execution

Centralized Training with Decentralized Execution





Parameter Sharing




边栏推荐
- On the concept and application of filtering in radar signal processing
- Cross modal semantic association alignment retrieval - image text matching
- Scheme selection and scheme design of multifunctional docking station for type C to VGA HDMI audio and video launched by ange in Taiwan | scheme selection and scheme explanation of usb-c to VGA HDMI c
- Complete model training routine
- 2022 new examination questions for crane driver (limited to bridge crane) and question bank for crane driver (limited to bridge crane) operation examination
- 2022 low voltage electrician examination content and low voltage electrician simulation examination question bank
- Transportation, new infrastructure and smart highway
- 2021-03-06 - play with the application of reflection in the framework
- 7. Regularization application
- Smart grid overview
猜你喜欢
3. MNIST dataset classification
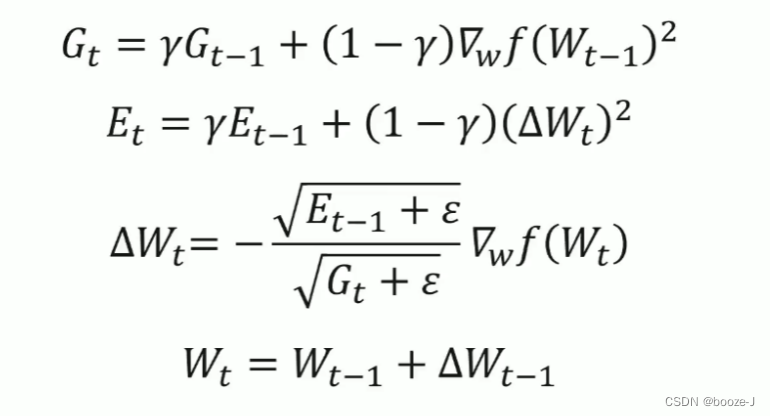
8. Optimizer
Two methods for full screen adaptation of background pictures, background size: cover; Or (background size: 100% 100%;)
11. Recurrent neural network RNN

2021-03-14 - play with generics
Basic realization of line chart (II)
Led serial communication

The Ministry of housing and urban rural development officially issued the technical standard for urban information model (CIM) basic platform, which will be implemented from June 1
Guojingxin center "APEC investment +": some things about the Internet sector today | observation on stabilizing strategic industrial funds
5. Over fitting, dropout, regularization
随机推荐
On the concept and application of filtering in radar signal processing
跨模态语义关联对齐检索-图像文本匹配(Image-Text Matching)
Study notes of single chip microcomputer and embedded system
Introduction to the types and repair methods of chip Eco
Transportation, new infrastructure and smart highway
High quality USB sound card / audio chip sss1700 | sss1700 design 96 kHz 24 bit sampling rate USB headset microphone scheme | sss1700 Chinese design scheme explanation
国内首次,3位清华姚班本科生斩获STOC最佳学生论文奖
2022 chemical automation control instrument examination summary and chemical automation control instrument simulation examination questions
2022 free test questions of fusion welding and thermal cutting and summary of fusion welding and thermal cutting examination
10. CNN applied to handwritten digit recognition
10.CNN应用于手写数字识别
Serial port receives a packet of data
130. Surrounding area
Vs code configuration latex environment nanny level configuration tutorial (dual system)
Kuntai ch7511b scheme design | ch7511b design EDP to LVDS data | pin to pin replaces ch7511b circuit design
1.线性回归
2021-03-14 - play with generics
Cross modal semantic association alignment retrieval - image text matching
Cs5261type-c to HDMI alternative ag9310 | ag9310 alternative
Ag7120 and ag7220 explain the driving scheme of HDMI signal extension amplifier | ag7120 and ag7220 design HDMI signal extension amplifier circuit reference