当前位置:网站首页>Fluentd is easy to use. Combined with the rainbow plug-in market, log collection is faster
Fluentd is easy to use. Combined with the rainbow plug-in market, log collection is faster
2022-07-07 08:19:00 【Rainbond】

There was an article about EFK(Kibana + ElasticSearch + Filebeat) Plug in log collection .Filebeat The plug-in is used to forward and centralize log data , And forward them to Elasticsearch or Logstash To index , but Filebeat As Elastic A member of the , Only in Elastic Used throughout the system .
Fluentd
Fluentd It's an open source , Distributed log collection system , From different services , Data source collection log , Filter logs , Distributed to a variety of storage and processing systems . Support for various plug-ins , Data caching mechanism , And it requires very few resources , Built in reliability , Combined with other services , It can form an efficient and intuitive log collection platform .
This article is introduced in Rainbond Use in Fluentd plug-in unit , Collect business logs , Output to multiple different services .
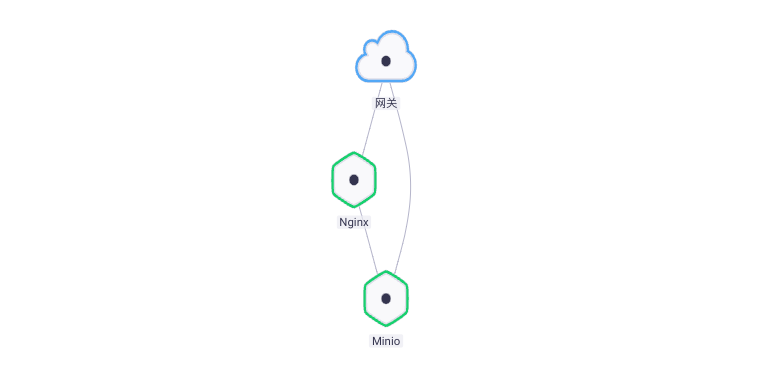
One 、 Integration Architecture
When collecting component logs , Just open in the component Fluentd plug-in unit , This article will demonstrate the following two ways :
- Kibana + ElasticSearch + Fluentd
- Minio + Fluentd
We will Fluentd Made into Rainbond Of General type plug-ins , After the app starts , The plug-in also starts and automatically collects logs for output to multiple service sources , The whole process has no intrusion into the application container , And strong expansibility .
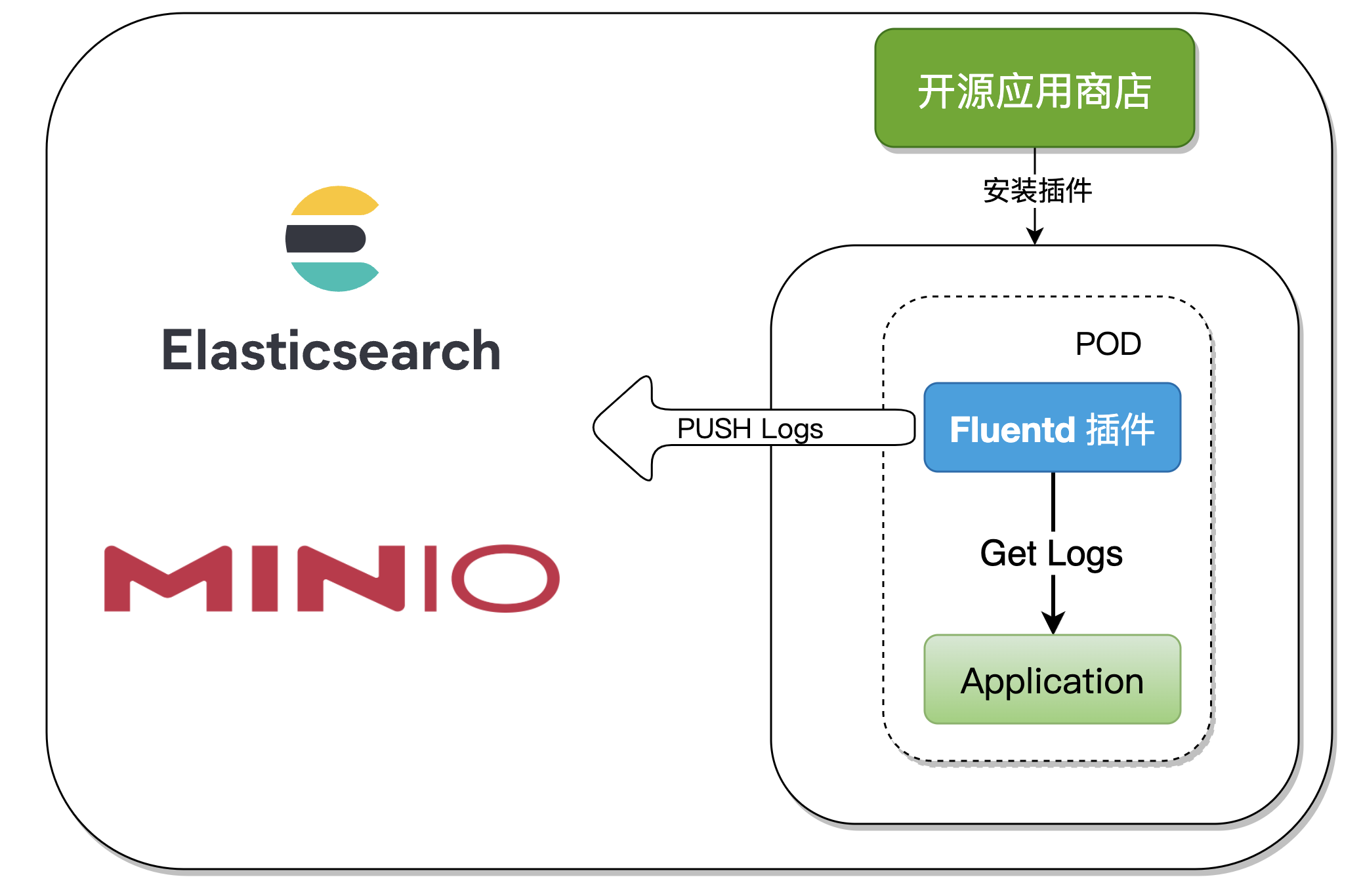
Two 、 Plug in principle analysis
Rainbond V5.7.0 There's a new : Install plug-ins from the open source app store , The plug-ins in this article have been released to the open source app store , When we use it, we can install it with one click , Modify the configuration file as required .
Rainbond The plug-in architecture is relative to Rainbond Part of the application model , The plug-in is mainly used to realize the application container extension operation and maintenance capability . The implementation of operation and maintenance tools has great commonality , Therefore, the plug-in itself can be reused . The plug-in must be bound to the application container to have runtime state , To realize an operation and maintenance capability , For example, performance analysis plug-ins 、 Network governance plug-in 、 Initialize the type plug-in .
In the production Fluentd In the process of plug-in , Using the General type plug-ins , You can think of it as one POD Start two Container,Kubernetes Native supports a POD Start multiple Container, But the configuration is relatively complex , stay Rainbond The plug-in implementation in makes the user operation easier .
3、 ... and 、EFK Log collection practices
Fluentd-ElasticSearch7 The output plug-in writes log records to Elasticsearch. By default , It uses batch API Create record , The API In a single API Call to perform multiple index operations . This reduces overhead and can greatly improve indexing speed .
3.1 Operation steps
application (Kibana + ElasticSearch) And plug-ins (Fluentd) Can be deployed with one click through the open source app store .
- Connect with the open source app store
- Search the app store for
elasticsearchAnd install7.15.2edition . - Team view -> plug-in unit -> Install from the app store
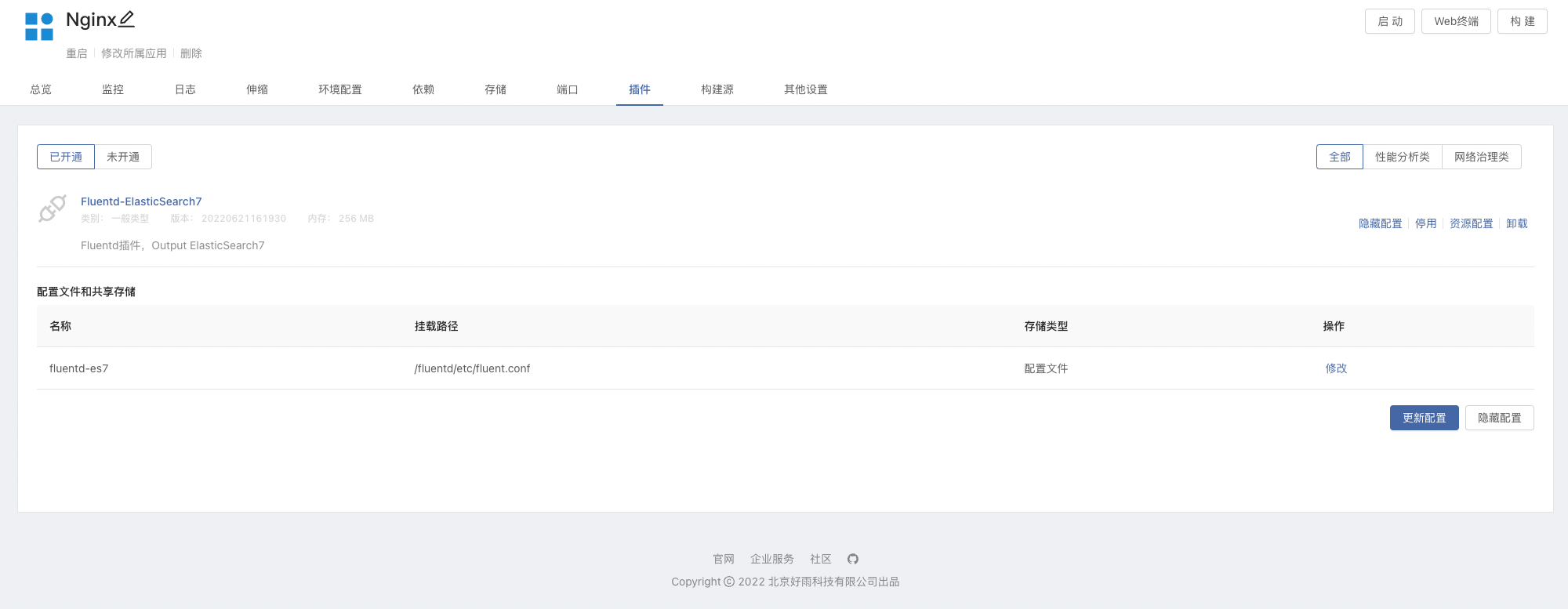
Fluentd-ElasticSearch7plug-in unit - Create components based on images , Mirror usage
nginx:latest, And mount storagevar/log/nginx. Use hereNginx:latestAs a demonstration- After the storage is mounted in the component , The plug-in will also mount the storage on its own , And access to Nginx Generated log files .
- stay Nginx Open plug-ins in the component , It can be modified as needed
FluentdThe configuration file , Refer to the profile introduction section below .
- add to ElasticSearch rely on , take Nginx Connect to ElasticSearch, Here's the picture :
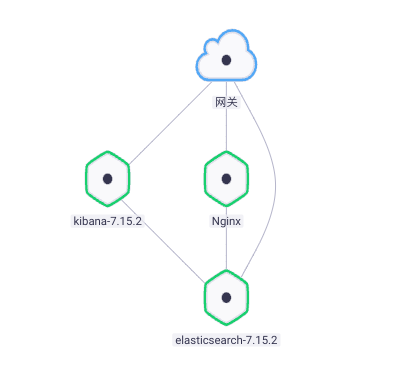
visit
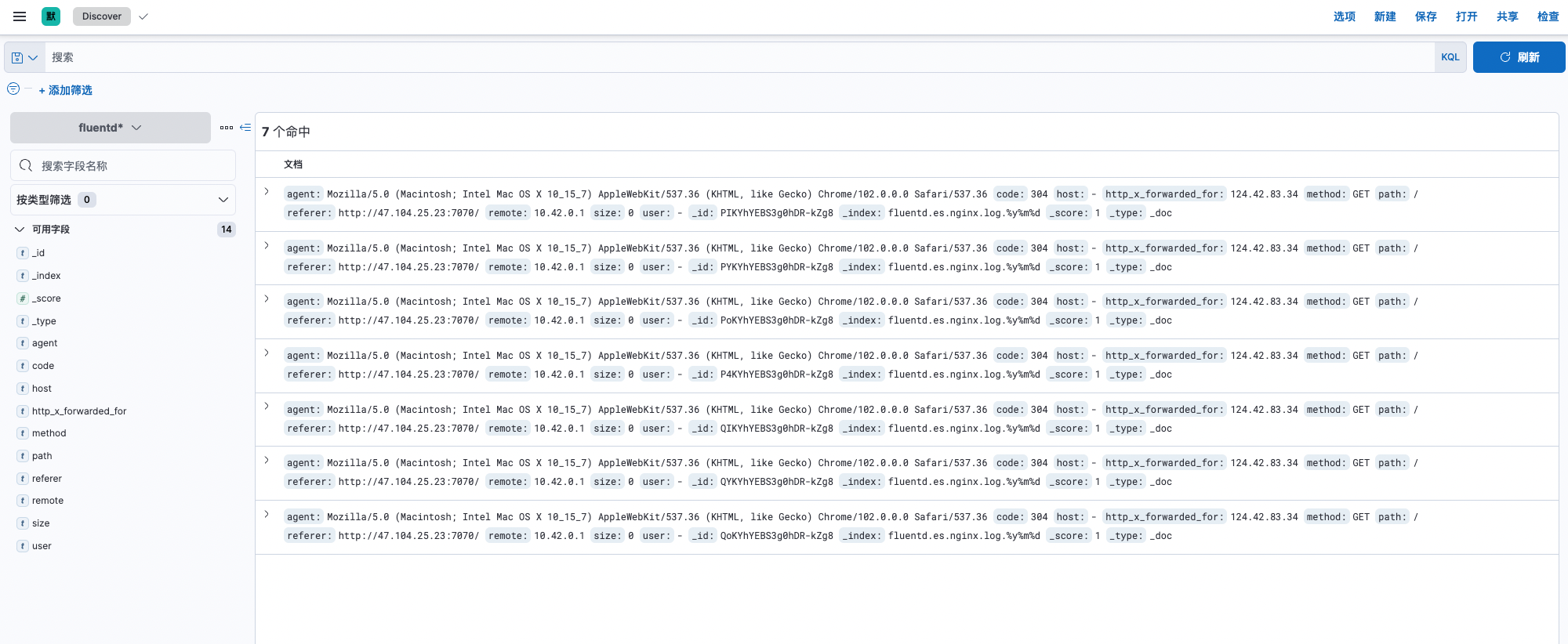
Kibanapanel , Enter into Stack Management -> data -> Index management , You can see that the existing index name isfluentd.es.nginx.log,visit
Kibanapanel , Enter into Stack Management -> Kibana -> Index mode , Create index mode .Enter into Discover, The log is displayed normally .
3.2 Profile Introduction
Profile reference Fluentd file output_elasticsearch.
<source> @type tail path /var/log/nginx/access.log,/var/log/nginx/error.log pos_file /var/log/nginx/nginx.access.log.pos <parse> @type nginx </parse> tag es.nginx.log</source><match es.nginx.**> @type elasticsearch log_level info hosts 127.0.0.1 port 9200 user elastic password elastic index_name fluentd.${tag} <buffer> chunk_limit_size 2M queue_limit_length 32 flush_interval 5s retry_max_times 30 </buffer></match>Configuration item explanation :
<source></source> The input source of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | Collection log type ,tail Indicates that the log contents are read incrementally |
| path | Log path , Multiple paths can be separated by commas |
| pos_file | Used to mark the file that has been read to the location (position file) Path |
| <parse></parse> | Log format analysis , According to your own log format , Write corresponding parsing rules . |
<match></match> The output of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | The type of service output to |
| log_level | Set the output log level to info; The supported log levels are :fatal, error, warn, info, debug, trace. |
| hosts | elasticsearch The address of |
| port | elasticsearch The port of |
| user/password | elasticsearch User name used / password |
| index_name | index The name of the definition |
| <buffer></buffer> | Log buffer , Used to cache log events , Improve system performance . Memory is used by default , You can also use file file |
| chunk_limit_size | Maximum size of each block : Events will be written to blocks , Until the size of the block becomes this size , The default memory is 8M, file 256M |
| queue_limit_length | The queue length limit for this buffer plug-in instance |
| flush_interval | Buffer log flush event , Default 60s Refresh the output once |
| retry_max_times | Maximum number of times to retry failed block output |
The above is only part of the configuration parameters , Other configurations can be customized with the official website documents .
Four 、Fluentd + Minio Log collection practices
Fluentd S3 The output plug-in writes log records to the standard S3 Object storage service , for example Amazon、Minio.
4.1 Operation steps
application (Minio) And plug-ins (Fluentd S3) Can be deployed with one click through the open source application store .
Connect with the open source app store . Search the open source app store for
minio, And install22.06.17edition .Team view -> plug-in unit -> Install from the app store
Fluentd-S3plug-in unit .visit Minio 9090 port , The user password is Minio Components -> Get from dependency .
establish Bucket, Custom name .
Get into Configurations -> Region, Set up Service Location
- Fluentd In the configuration file of the plug-in
s3_regionThe default isen-west-test2.
- Fluentd In the configuration file of the plug-in
Create components based on images , Mirror usage
nginx:latest, And mount storagevar/log/nginx. Use hereNginx:latestAs a demonstration- After the storage is mounted in the component , The plug-in will also mount the storage on its own , And access to Nginx Generated log files .
Enter into Nginx In component , Opening Fluentd S3 plug-in unit , Modify... In the configuration file
s3_buckets3_region
- Build dependencies ,Nginx Component dependency Minio, Update the component to make it effective .
- visit Nginx service , Let it generate logs , In a moment, you can Minio Of Bucket see .

4.2 Profile Introduction
Profile reference Fluentd file Apache to Minio.
<source> @type tail path /var/log/nginx/access.log pos_file /var/log/nginx/nginx.access.log.pos tag minio.nginx.access <parse> @type nginx </parse></source><match minio.nginx.**> @type s3 aws_key_id "#{ENV['MINIO_ROOT_USER']}" aws_sec_key "#{ENV['MINIO_ROOT_PASSWORD']}" s3_endpoint http://127.0.0.1:9000/ s3_bucket test s3_region en-west-test2 time_slice_format %Y%m%d%H%M force_path_style true path logs/ <buffer time> @type file path /var/log/nginx/s3 timekey 1m timekey_wait 10s chunk_limit_size 256m </buffer></match>Configuration item explanation :
<source></source> The input source of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | Collection log type ,tail Indicates that the log contents are read incrementally |
| path | Log path , Multiple paths can be separated by commas |
| pos_file | Used to mark the file that has been read to the location (position file) Path |
| <parse></parse> | Log format analysis , According to your own log format , Write corresponding parsing rules . |
<match></match> The output of the log :
| Configuration item | interpretative statement |
|---|---|
| @type | The type of service output to |
| aws_key_id | Minio user name |
| aws_sec_key | Minio password |
| s3_endpoint | Minio Access address |
| s3_bucket | Minio Bucket name |
| force_path_style | prevent AWS SDK Destroy endpoint URL |
| time_slice_format | Each file name is stamped with this time stamp |
| <buffer></buffer> | Log buffer , Used to cache log events , Improve system performance . Memory is used by default , You can also use file file |
| timekey | Every time 60 Seconds to refresh the accumulated chunk |
| timekey_wait | wait for 10 Seconds to refresh |
| chunk_limit_size | Maximum size of each block |
Last
Fluentd The plug-in can flexibly collect business logs and output multiple services , And combine Rainbond One click installation in plug-in market , Make our use easier 、 quick .
at present Rainbond Open source plug-in application market Flunetd Plugins are just Flunetd-S3Flunetd-ElasticSearch7, Welcome to contribute plug-ins !
边栏推荐
- 通俗易懂单点登录SSO
- Give full play to the wide practicality of maker education space
- Qinglong panel -- Huahua reading
- Automatic upgrading of database structure in rainbow
- Network learning (II) -- Introduction to socket
- Complete linear regression manually based on pytoch framework
- Uniapp mobile terminal forced update function
- Leetcode medium question my schedule I
- [IELTS speaking] Anna's oral learning records Part3
- Use of out covariance and in inversion in kotlin
猜你喜欢

解读创客思维与数学课程的实际运用

The simple problem of leetcode is to judge whether the number count of a number is equal to the value of the number

Vulnerability recurrence easy_ tornado

Don't stop chasing the wind and the moon. Spring mountain is at the end of Pingwu
rsync远程同步

CCTV is so warm-hearted that it teaches you to write HR's favorite resume hand in hand

船载雷达天线滑环的使用

发挥创客教育空间的广泛实用性
Use of JMeter
Easy to understand SSO
随机推荐
Interpreting the practical application of maker thinking and mathematics curriculum
接口作为参数(接口回调)
使用 Nocalhost 开发 Rainbond 上的微服务应用
Give full play to the wide practicality of maker education space
Real time monitoring of dog walking and rope pulling AI recognition helps smart city
JS cross browser parsing XML application
Analysis of maker education in innovative education system
Uniapp mobile terminal forced update function
jeeSite 表单页面的Excel 导入功能
Complex network modeling (I)
[quick start of Digital IC Verification] 13. SystemVerilog interface and program learning
单元测试报告成功率低
Qinglong panel -- Huahua reading
[go ~ 0 to 1] obtain timestamp, time comparison, time format conversion, sleep and timer on the seventh day
使用BiSeNet实现自己的数据集
Hisense TV starts the developer mode
Make LIVELINK's initial pose consistent with that of the mobile capture actor
调用 pytorch API完成线性回归
面试题(CAS)
藏书馆App基于Rainbond实现云原生DevOps的实践