当前位置:网站首页>Eklavya -- infer the parameters of functions in binary files using neural network
Eklavya -- infer the parameters of functions in binary files using neural network
2022-07-02 07:52:00 【MezereonXP】
EKLAVYA – Using neural network to infer the parameters of functions in binary files
List of articles
This time I will introduce an article , be known as Neural Nets Can Learn Function Type Signatures From Binaries
From the National University of Singapore Zhenkai Liang The team , It's in Usenix Security 2017 On
Problem introduction and formal definition
The main concern of this work is function parameter inference , There are two parts :
- Number of parameters
- Type of parameter , such as int, float etc.
Traditional methods usually use some prior knowledge , take Semantics of instructions ,ABI practice (Application Binary Interface), Compiler style And so on .
Once the compiler changes , The instruction set has changed , Then we need to reintroduce some prior knowledge .
If we can get rid of , Or reduce the use of these prior knowledge , Then there will be no restriction !
that , Use neural networks for automated learning and inference , It's just a way of thinking .
Presupposition
- We can first know the boundary of a function (boundary)
- Inside a function , We know its instruction boundary
- We know that it represents a function call (function dispatch) Instructions , such as call
Through the disassembly tool , We can satisfy the above assumptions .
It is worth mentioning that , Function boundaries can also be done using neural networks , Interested readers can refer to Dawn Song Hair in Usenix Security 2015 Of Recognizing functions in binaries with neural networks.
here , First, give some definitions of symbols :
We define our model as M ( ⋅ ) M(\cdot) M(⋅)
Defined function a a a The disassembled code is T a T_a Ta , T a [ i ] T_a[i] Ta[i] Representative function a a a Of the i i i Bytes
function a a a Of the k k k Instructions can be written as I a [ k ] : = < T a [ m ] , T a [ m + 1 ] , . . . , T a [ m + l ] > I_a[k]:= <T_a[m], T_a[m+1],...,T_a[m+l]> Ia[k]:=<Ta[m],Ta[m+1],...,Ta[m+l]>
- among m m m Is the position index of the starting byte of the corresponding instruction
- l l l Is the number of bytes contained in the instruction
A contain p p p Functions of instructions a a a Can be expressed as T a : = < I a [ 1 ] , I a [ 2 ] , I a [ p ] > T_a:=<I_a[1],I_a[2],I_a[p]> Ta:=<Ia[1],Ia[2],Ia[p]>
If a function b b b There is a direct call call For the function a a a, We will this article call Take out all the instructions before the instructions , be called caller snippet, It can be translated into Caller fragment . Defined as C b , a [ j ] : = < I b [ 0 ] , . . . , I b [ j − 1 ] > C_{b,a}[j]:=<I_b[0],...,I_b[j-1]> Cb,a[j]:=<Ib[0],...,Ib[j−1]>
- among I b [ j ] I_b[j] Ib[j] Corresponding call function a a a The order of
- If I b [ j ] I_b[j] Ib[j] Is an indirect call , We make C b , a [ j ] : = ∅ C_{b,a}[j]:=\empty Cb,a[j]:=∅
We will collect functions a a a Caller fragments of all callers of , Write it down as D a : = T a ∪ ( ⋃ b ∈ S a ( ⋃ 0 ≤ j ≤ ∣ T b ∣ C a , b [ j ] ) ) \mathcal{D}_a:=T_a\cup(\bigcup_{b\in S_a}(\bigcup_{0\leq j\leq |T_b|}C_{a,b}[j])) Da:=Ta∪(⋃b∈Sa(⋃0≤j≤∣Tb∣Ca,b[j]))
- among S a S_a Sa Is to call a a a A collection of all functions of
Because the length of the caller fragment can be very long , Here the article is set to no more than 500 Orders
Our function M ( ⋅ ) M(\cdot) M(⋅) Accept input D a \mathcal{D}_a Da , Output two variables :
- function a a a The number of parameters
- function a a a The type of each parameter of
- C- The parameter type of style can be defined as int, char, float, void*, enum, union, struct
Methods to design
Let's first give the overall method flow chart :
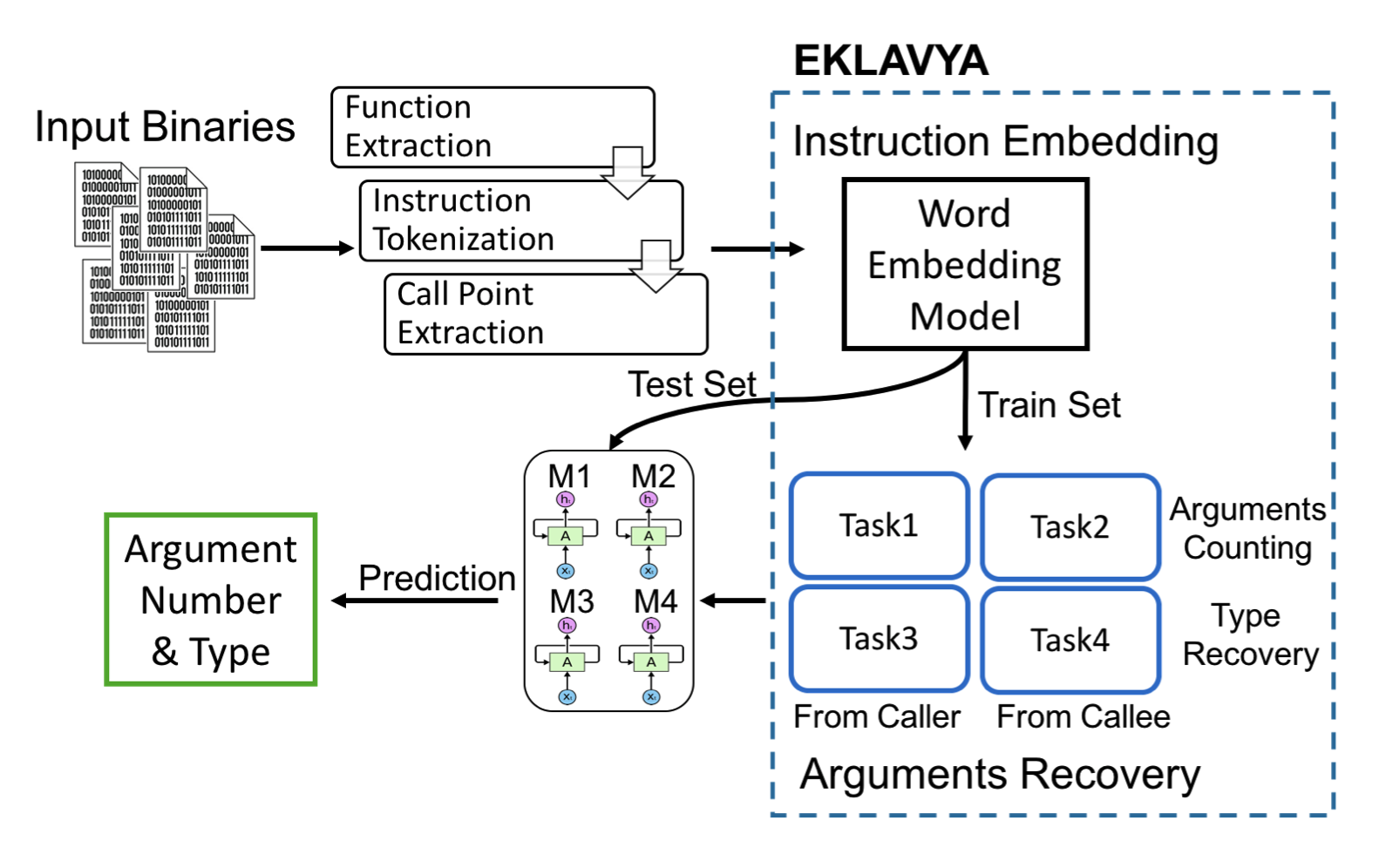
Simply speaking , It can be divided into two modules :
- Instruction encoding module
- First , Extract the input binary file 、 The division of instructions 、 Extraction of call points .
- Then the instructions are Word Embedding code , Get the corresponding vector representation , This part can refer to NLP Medium Word2Vec.
- Parameter restore module
- Divide these data into training set and test set , Separate use 4 A recurrent neural network (RNN) Come from two aspects ( Caller and callee ) Infer the number and type of function parameters , That is, it corresponds to 4 A mission (Task2,Task4 Corresponding to the callee ,Task1,Task3 Corresponding to the caller ).
How to infer multiple parameter types ?
One RNN, Enter a sequence , Only one type can be inferred .
So the implementation of this article is , Train more than one RNN, every last RNN Independently infer the parameter type of the fixed position .
With a first RNN Infer the number of parameters , Then use multiple RNN To infer the parameters of different positions .
Data preparation
This article uses some linux My bag , And then use clang and gcc To compile , By setting debug Pattern , You can go directly to binary Medium DWARF Field to find the corresponding function boundary 、 Number and type of parameters , As ground truth.
Two data sets are built :
- Data sets 1: Contains 3 A popular linux package (binutils,coreutils as well as findutils), Used O0 To O3 The optimization level of
- Data sets 2: Put the dataset 1 Contains linux Package expansion , Increase more 5 individual (sg3utils, utillinux, inetutils, diffutils and usbutils), Also in the 4 Compile on an optimization level
The division ratio of training set and test set is 8:2
Unbalanced data
In the construction of data sets , There will be a large difference in the proportion of different types of data . For example, the parameter is pointer Type of data is union Hundreds of times the type , Most functions are less than 3 Parameters . This article does not solve this problem .
experimental result
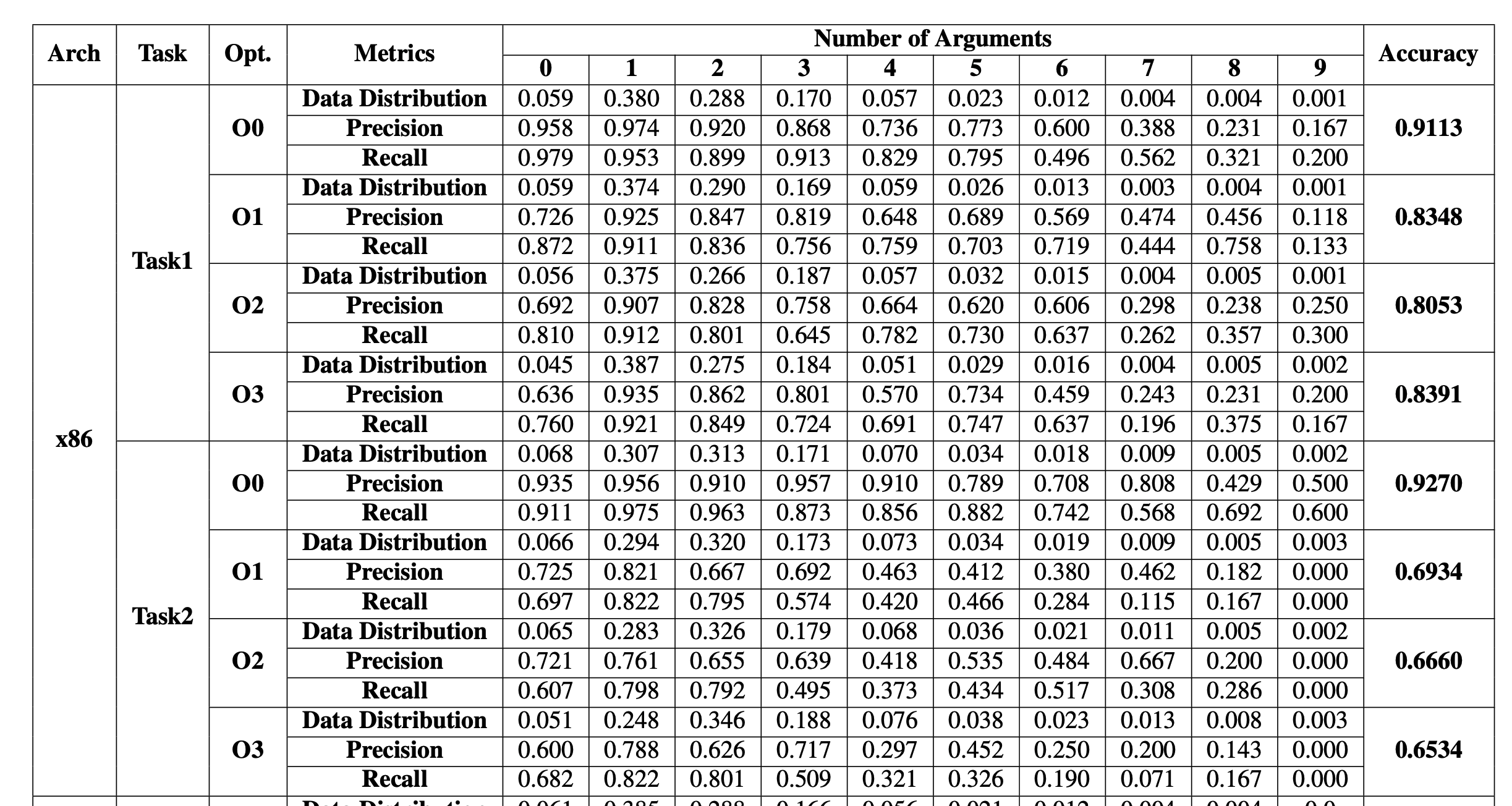
Post it here Task1 and Task2, That is, through the caller and the callee , The result of inferring the number of parameters
You can see :
- The higher the optimization level , The harder it is to infer , But there is no strict increasing relationship
- The more parameters , The harder it is to infer , It is also related to the amount of training data
- From the caller , It is easier to infer the number of parameters

It's on it , About the result of parameter type inference
You can see :
- The optimization level seems to be less intrusive , Even the higher the optimization level , The more accurate the inference type
- The farther back the parameter is , The harder it is to infer the type
- Infer from the caller and the callee , The difference is not great
边栏推荐
- open3d学习笔记二【文件读写】
- 自然辩证辨析题整理
- EKLAVYA -- 利用神经网络推断二进制文件中函数的参数
- 【Mixed Pooling】《Mixed Pooling for Convolutional Neural Networks》
- Faster-ILOD、maskrcnn_ Benchmark installation process and problems encountered
- 超时停靠视频生成
- ModuleNotFoundError: No module named ‘pytest‘
- Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations
- 深度学习分类优化实战
- Implementation of yolov5 single image detection based on pytorch
猜你喜欢

MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
用全连接层替代掉卷积 -- RepMLP
【学习笔记】反向误差传播之数值微分

【TCDCN】《Facial landmark detection by deep multi-task learning》

Sorting out dialectics of nature

【Paper Reading】
【Batch】learning notes
自然辩证辨析题整理

深度学习分类优化实战
随机推荐
Open3D学习笔记一【初窥门径,文件读取】
win10+vs2017+denseflow编译
Convert timestamp into milliseconds and format time in PHP
Implementation of yolov5 single image detection based on onnxruntime
Apple added the first iPad with lightning interface to the list of retro products
(15) Flick custom source
【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
Comparison of chat Chinese corpus (attach links to various resources)
【Random Erasing】《Random Erasing Data Augmentation》
A slide with two tables will help you quickly understand the target detection
open3d环境错误汇总
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
open3d学习笔记五【RGBD融合】
Timeout docking video generation
Handwritten call, apply, bind
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
【Programming】
用MLP代替掉Self-Attention
超时停靠视频生成