当前位置:网站首页>5 minutes to master machine learning iris logical regression classification
5 minutes to master machine learning iris logical regression classification
2022-07-06 14:35:00 【ブリンク】
This article will use 5 Minutes to help you master the most classic case of iris classification in machine learning .
sketch
Use scikit-learn library , coordination Numpy、Pandas It can make machine learning simple , Utilization based on Matplotlib Of seaborn Libraries make it easier to visualize .
First, import the library you want to use :
from sklearn import datasets
# We from sklearn You can get the data in your own data set
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.linear_model import LogisticRegression
# Use logistic regression to learn
from sklearn.model_selection import train_test_split
# Use it to segment data into training set and test set
Import data
sklearn We have prepared some data sets for practice , Including the iris data to be used now , We just need to use datasets Of l o a d i r i s ( ) load_iris() loadiris() The method can :
iris_data = datasets.load_iris()
Got iris_data yes sklearn Type included in , We can use i r i s . k e y s ( ) iris.keys() iris.keys() Method to see what it contains , He will return a dictionary :
>>> iris.keys()
dict_keys(['data', 'target', 'frame',
'target_names', 'DESCR', 'feature_names',
'filename', 'data_module'])
It includes 150 Group data ,data Indicates the included data ,target It means label , That is, what kind of iris this flower belongs to , The iris in the data has 3 Kind of setosa, versicolor and virginica, They are contained in target_names in , Indicates the name of the label .feature_names Indicates the name of the feature , That is, the description of the characteristics of iris , For example, there are petal lengths in the data set 、 Width and calyx length 、 Width . The rest is not used in this example , Don't introduce too much .
Next, extract the data and labels , And stored in Pandas Of DataFrame in ,:
>>> data = iris.data
>>> data = data.pd.DataFrame(data,columns = iris.target_names)
# Change the column name to the name of the feature
>>> data.head()
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
Data visualization
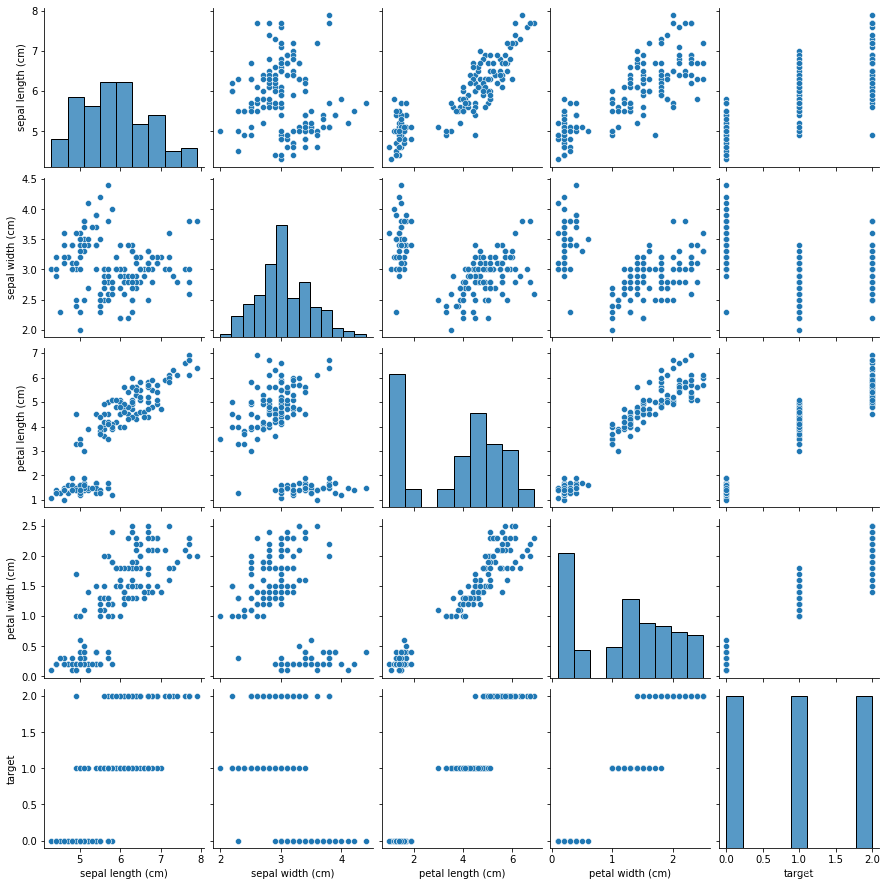
Use seaborn Of p a i r p l o t ( ) pairplot() pairplot() Method can quickly view the relationship between each two variables , Including with themselves :
sns.pairplot(data)
model
Use sklearn The estimator of builds a logistic regression model :
modle = LogisticRegression()
Data preprocessing
First, all the data is processed into training set and test set , So that we can test the model , Use train_test_split() Method can easily do this , It will return separately x Training set ,x Test set ,y Training set ,y Test set :
x_train,x_test,y_train,y_test = train_test_split(X=data,y=iris.target,train_size=0.8)
# 80% As a training set The rest are used as test sets
Training models
Using estimators f i t ( ) fit() fit() The method can train the model :
model.fit(x_train,y_train)
Model to evaluate
Can be directly estimated s c o r e ( ) score() score() Methods calculate the score or accuracy of the model under the test set :
>>> model.score(x_test,y_test)
0.9333333333333333 # The accuracy rate has reached 93.33%, This is related to the division of training set and testing machine
Model to predict
The trained model can be used to predict the test machine data , in other words , When you know a set of data about the characteristics of iris , You can use this model to know which kind it belongs to :
>>> s = model.predict(x_test)
array([1, 2, 1, 2, 1, 0, 2, 1, 0,
0, 0, 2, 1, 0, 2, 0, 1, 2,
1, 1, 2, 2,1, 2, 0, 2, 1, 2, 0, 0])
# among 0 Express setosa,1 Express versicolor,2 Express virginica
边栏推荐
- “人生若只如初见”——RISC-V
- 《统计学》第八版贾俊平第五章概率与概率分布
- Record an API interface SQL injection practice
- Record once, modify password logic vulnerability actual combat
- 网络基础详解
- Always of SystemVerilog usage_ comb 、always_ iff
- 关于超星脚本出现乱码问题
- Internet Management (Information Collection)
- 函数:求两个正数的最大公约数和最小公倍
- Mysql的事务是什么?什么是脏读,什么是幻读?不可重复读?
猜你喜欢
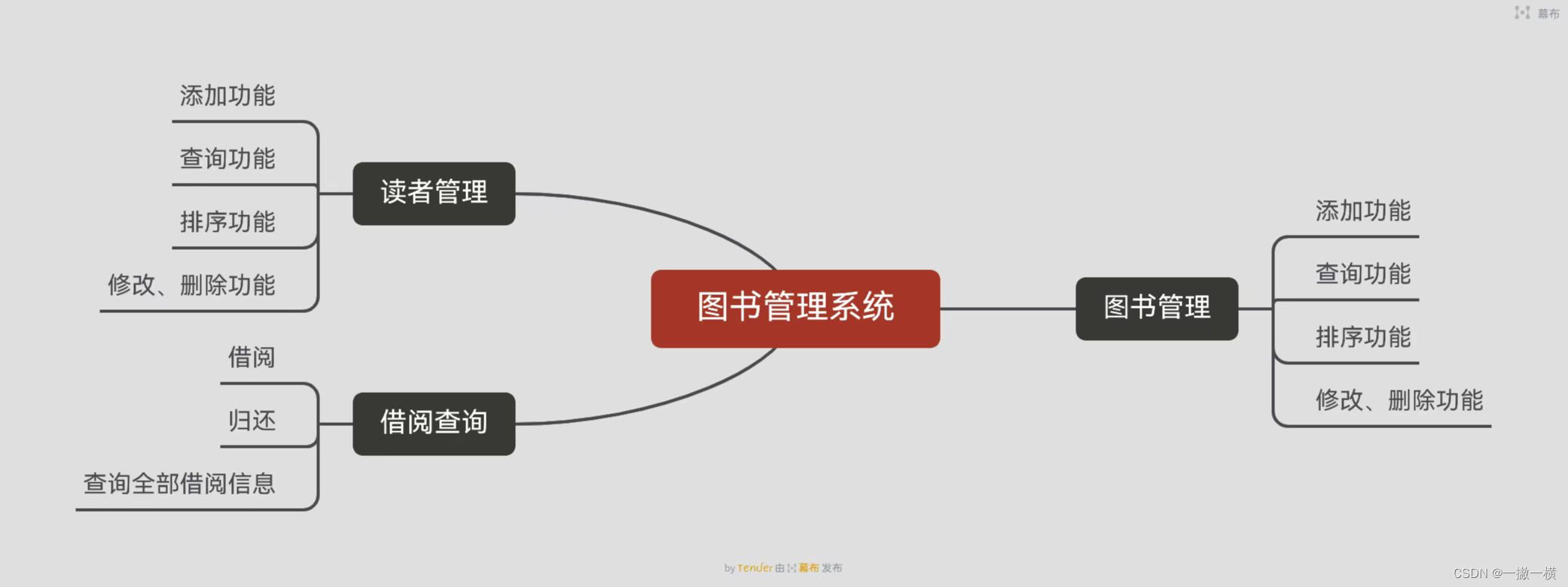
Library management system
Hackmyvm target series (1) -webmaster
攻防世界MISC练习区(SimpleRAR、base64stego、功夫再高也怕菜刀)

JDBC事务、批处理以及连接池(超详细)

Apache APIs IX has the risk of rewriting the x-real-ip header (cve-2022-24112)
Tencent map circle
内网渗透之内网信息收集(二)
On the idea of vulnerability discovery
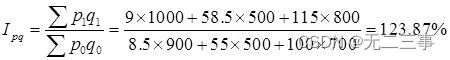
《统计学》第八版贾俊平第十四章指数知识点总结及课后习题答案

Network technology related topics
随机推荐
浙大版《C语言程序设计实验与习题指导(第3版)》题目集
【指针】求解最后留下的人
数字电路基础(四) 数据分配器、数据选择器和数值比较器
Chain team implementation (C language)
Overview of LNMP architecture and construction of related services
函数:求1-1/2+1/3-1/4+1/5-1/6+1/7-…+1/n
Data mining - a discussion on sample imbalance in classification problems
Detailed explanation of three ways of HTTP caching
网络基础之路由详解
Interview Essentials: what is the mysterious framework asking?
. Net6: develop modern 3D industrial software based on WPF (2)
Intranet information collection of Intranet penetration (3)
The most popular colloquial system explains the base of numbers
【指针】删除字符串s中的所有空格
安全面试之XSS(跨站脚本攻击)
循环队列(C语言)
Always of SystemVerilog usage_ comb 、always_ iff
[paper reproduction] cyclegan (based on pytorch framework) {unfinished}
【指针】求二维数组中最大元素的值
MySQL interview questions (4)