当前位置:网站首页>MySQL优化
MySQL优化
2022-07-02 06:27:00 【programmercherry】
1. 应用优化
1.1. 使用数据库连接池
对于访问数据库来说,建立连接的代价是比较昂贵的,因为我们频繁的创建关闭连接,是比较耗费资源的,所以,有必要建立 数据库连接池 以提高访问的性能。
1.2. 减少对MySQL的访问
1.2.1. 避免对数据进行重复检索
在编写代码时,理清对数据库的访问逻辑,能够一次连接获取结果的,就不用两次连接
select id, name from student;
select id, age from student;
-- 这样,就需要向数据库提交两次请求,数据库需要做两次查询操作,可优化成一条语句
select id, name, age from student;
1.2.2. 增加 cache 层
在应用中,增加 缓存层 来 减轻数据库负担。缓存层有很多种,也有很多实现方式。
可以将部分数据从数据库中抽取出来放到应用端 以文本方式存储,或者使用框架(Mybatis, Hibernate)提供的一级缓存/二级缓存,或者使用redis数据库来缓存数据。
1.3. 负载平衡
负载平衡 是应用中使用非常普遍的一种优化方法,它的机制就是利用某种均衡算法,将固定的负载量 分布到 不同的服务器上,以此,来降低单台服务器的负载,达到优化的效果。
1.3.1. 利用MySQL复制分流查询
通过MySQL的主从复制,实现读写分离,使增删改查操作走主节点,查询操作走从节点,从而可以降低单台服务器的读写压力。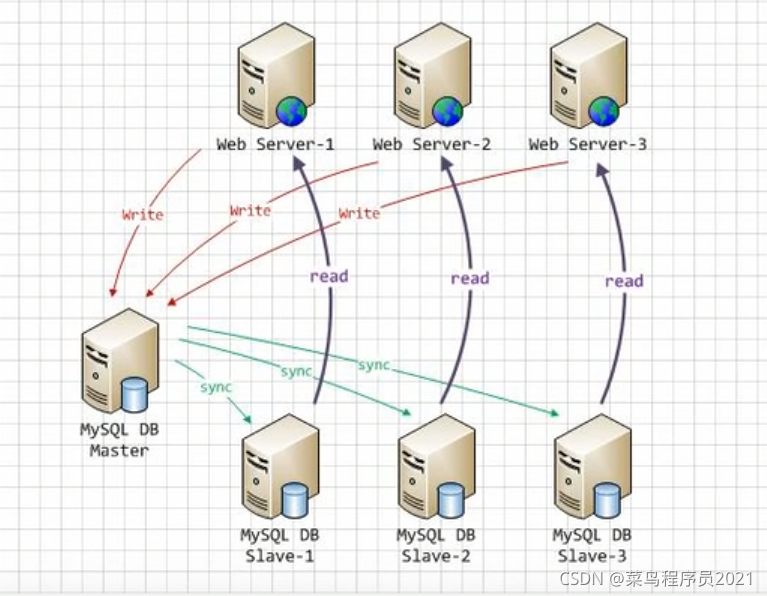
1.3.2. 采用分布式数据库架构
分布式数据库架构适合大数据量、负载高的情况,它有良好的拓展性和高可用性。通过在多台服务器之间分布数据,可以实现在多台服务器之间的负载均衡,提高访问效率。
2. MySQL中查询缓存优化
开启MySQL的查询缓存,当执行完全相同的SQL语句的时候,服务器就会直接从缓存中读取结果。
当数据被修改,之前的缓存会失效,修改比较频繁的表不适合做查询缓存。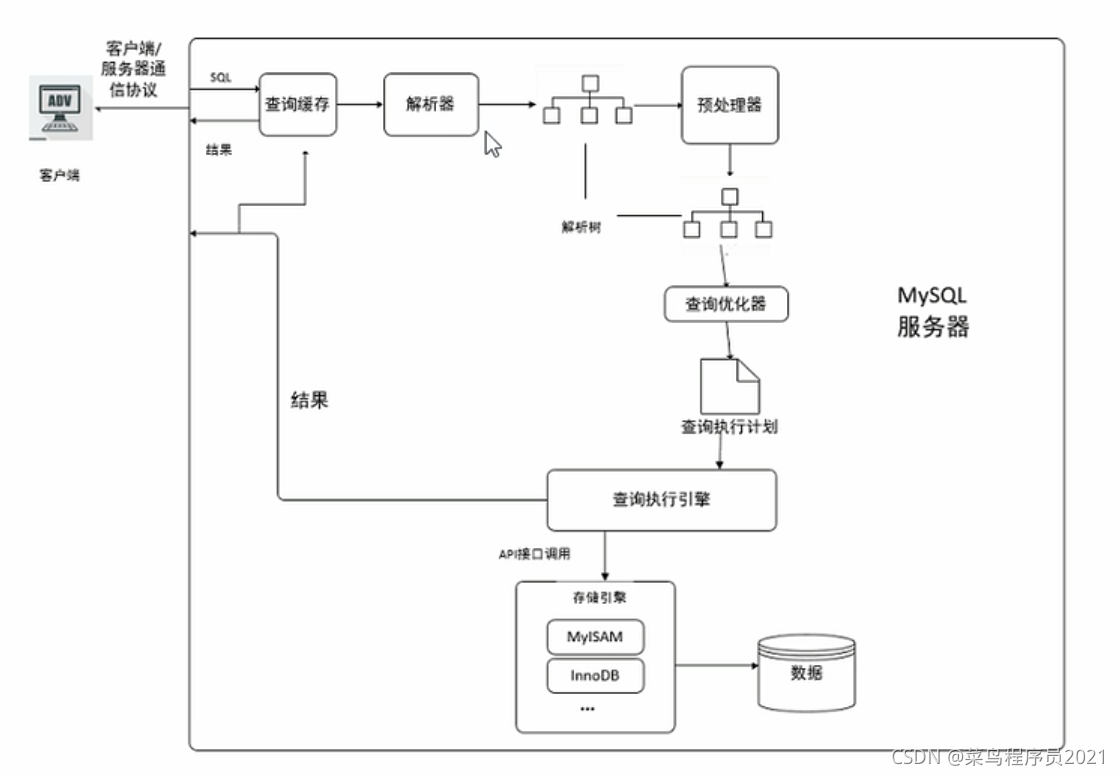
- 客户端发送一条查询给服务器
- 服务器会先检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段
- 服务器进行 SQL 解析、预处理、再由 优化器 生成对应的 执行计划
- MySQL根据优化器生成的执行计划,调用 存储引擎的API 来执行查询
- 将结果返回客户端
2.1. 查询缓存配置
-- 查看当前的MySQL是否支持 查询缓存
show variables like 'have_query_cache';
-- 查看当前MySQL是否开启了查询缓存
show variables like 'query_cache_type';
-- 查看查询缓存的占用大小 默认是104876字节 = 1M
show variables like 'query_cache_size';
-- 查看查询缓存的状态变量
show status like 'Qcache%';
| 参数 | 含义 |
|---|---|
| Qcache_free_blocks | 查询缓存中的可用内存块数 |
| Qcache_free_memory | 查询缓存的可用内存量 |
| Qcache_hits | 查询缓存命中数 |
| Qcache_inserts | 添加到查询缓存的查询数 |
| Qcache_lowmem_prunes | 由于内存不足而从查询缓存中删除的查询数 |
| Qcache_not_cached | 非缓存查询的数量(由于query_cache_type设置而无法缓存或未缓存) |
| Qcache_queries_in_cache | 查询缓存中注册的查询数 |
| Qcache_total_blocks | 查询缓存中的块总数 |
2.2. 开启MySQL的查询缓存
MySQL的查询缓存默认是关闭的,需要手动设置配置参数 query_cache_type,来开启查询缓存,query_cache_type 该参数的可取值有三个:
| 值 | 含义 |
|---|---|
| off或0 | 查询缓存功能关闭 |
| on或1 | 查询缓存功能打开,select的结果符合缓存条件即会缓存,否则,不予缓存,显式指定SQL_NO_CACHE,不予缓存 |
| demand或2 | 查询缓存功能按需进行,显式指定SQL_CACHE的select语句才会缓存,其他均不予缓存 |
在Linux系统中,配置文件 /usr/my.cnf 中,增加以下配置:
# 开启MySQL的查询缓存 vim /etc/my.cnf 添加下条配置命令
query_cache_type = 1;
# 配置完成之后 重新MySQL
service mysql restart
2.3. 查询缓存select选项
可以在select语句中指定两个与查询缓存相关的选项:
SQL_CACHE:如果查询结果是可缓存的,并且 query_cache_type 系统变量的值为 ON 或 DEMAND ,则缓存查询结果。
SQL_NO_CACHE:服务器不使用查询缓存,它既不检查查询缓存,也不检查结果是否已缓存,也不缓存查询结果。
select sql_cache id,name from student;
select sql_no_cache id,name from student;
2.4. 查询缓存失效的情况
- SQL语句不同,包括大小写不同。要想命中查询缓存,查询的SQL语句必须完全一致。
- 当查询语句中有一些不确定信息时,则不会缓存,如 now(),current_date(),curdate(),curtime(),rand(),uuid(),user(),database()。
- 不使用任何表查询语句。
- 查询mysql,information_schema 或 performance_schema 数据库中的表时,不会走查询缓存。
- 在存储的函数,触发器或事件的主体内执行的查询。
- 如果表更改,则使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除。这包括使用merge 映射到已更改表的表的查询。一个表可以被许多类型的语句,如被改变 insert、update、delete、truncate table、alter table、drop table 或 drop database。
3. MySQL内存管理优化
- 尽可能多的内存分配给MySQL做缓存,但要给操作系统和其他程序预留足够内存
- MyISAM 存储引擎的数据文件读取依赖于操作系统自身的 IO 缓存,因此,如果有 MyISAM 表,就要预留更多的内存给操作系统做 IO 缓存
- 排序区、连接区等缓存是分配给每个数据会话(session)专用的,其默认值的设置要根据最大连接数合理分配,如果设置太大,不但浪费资源,而且在 并发连接 较高时 会导致物理内存耗尽。
3.1. MyISAM 内存优化
MyISAM 存储引擎使用 key_buffer 缓存索引块,加速 MyISAM 索引的读写速度。对于 MyISAM 表 的数据块,MyISAM 没有特别的缓存机制,完全依赖于操作系统的 IO 缓存。
key_buffer_size
key_buffer_size 决定 MyISAM 索引块缓存区的大小,直接影响到 MyISAM 表的存取效率。可以在 MyISAM 参数文件中设置 key_buffer_size 的值,对于一般 MyISAM 数据库,建议至少将 1/4 可用内存分配给 key_buffer_size 。
在 vim /etc/my.cnf 添加下条配置命令
key_buffer_size = 512M;
read_buffer_size
如果需要经常顺序扫描 MyISAM 表,可以通过增大 read_buffer_size 的值来改善性能。但需要注意的是 read_buffer_size 是每个session 独占的,如果默认值设置太大,就会造成内存浪费。
read_rnd_buffer_size
对于需要做排序 MyISAM 表的查询,如带有 order by 子句的 SQL,适当增加 read_rnd_buffer_size 的值,可以改善此类的SQL性能。但需要注意的是 read_buffer_size 是每个session 独占的,如果默认值设置太大,就会造成内存浪费。
3.2. InnoDB 内存优化
InnoDB 用一块内存区做 IO 缓存池,该缓存池不仅用来缓存 InnoDB 索引块,而且也用来缓存 InnoDB的数据块。
innodb_buffer_pool_size
该变量决定了 InnoDB存储引擎表数据和索引数据的最大缓存区大小。在保证操作系统及其他程序有足够内存可用的情况下,innodb_buffer_pool_size 的值越大,缓存命中率越高,访问 InnoDB 表需要的磁盘 IO 就越小,性能也越高innodb_buffer_pool_size = 512M
innodb_log_buffer_size
决定了 InnoDB 重做日志缓存的大小,对于可能产生大量更新记录的大事务,增加 innpodb_log_buffer_size 的大小,可以避免 InnoDB 在事务提交前就执行 不必要的日志写入磁盘操作。innpodb_log_buffer_size = 10M
4. MySQL并发参数调整
从实现上说,MySQL server 是多线程结构,包括后台线程和客户端服务线程。多线程可以有效利用服务器资源,提高数据库的并发性能。
在MySQL中,控制并发连接和线程的主要参数包括 max_connections、back_log 、 thread_cache_size、 table_open_cache、innodb_lock_wait_timeout
1. max_connections
采用max_connections 控制允许连接到 MySQL 数据库的最大数量,默认值是 151。
2. back_log
back_log 参数 控制MySQL 监听TCP端口时设置的积压请求栈大小。
如果MySQL的连接达到 max_connections 时,新的请求连接将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即 back_log
如果需要数据库在短时间内处理大量连接请求,可以考虑适当增大back_log 的值。
3. table_open_cache
该参数用来控制所有 SQL语句执行线程可打开缓存的数量,而在执行SQL语句时,每一个SQL执行线程至少要打开 1 个表缓存。
该参数的值应该根据设置的最大连接数 max_connections 以及每个连接执行关联查询中涉及的表的最大数量来设定。
4. thread_cache_size
为了加快连接数据库的速度,MySQL 会缓存一定数量的客户服务线程以备重用,通过参数 thread_cache_size 可控制MySQL 缓存客户服务线程的数量
5. innodb_lock_wait_timeout
该参数是用来设置 InnoDB 事务等待行锁的时间,默认值是50ms。
对于需要快速反馈的业务系统来说,可以将行锁的等待时间调小,以避免事务长时间挂起。
对于后台运行的批量处理程序来说,可以将行锁的等待时间调大,以避免发生大的回滚操作。
边栏推荐
- Feature Engineering: summary of common feature transformation methods
- 【Mixup】《Mixup:Beyond Empirical Risk Minimization》
- 【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
- 用MLP代替掉Self-Attention
- Replace self attention with MLP
- CVPR19-Deep Stacked Hierarchical Multi-patch Network for Image Deblurring论文复现
- 【Cascade FPD】《Deep Convolutional Network Cascade for Facial Point Detection》
- E-R画图明确内容
- I'll show you why you don't need to log in every time you use Taobao, jd.com, etc?
- [mixup] mixup: Beyond Imperial Risk Minimization
猜你喜欢
What if the laptop can't search the wireless network signal

open3d学习笔记三【采样与体素化】

浅谈深度学习中的对抗样本及其生成方法

Traditional target detection notes 1__ Viola Jones
Hystrix dashboard cannot find hystrix Stream solution
服务器的内网可以访问,外网却不能访问的问题

【BiSeNet】《BiSeNet:Bilateral Segmentation Network for Real-time Semantic Segmentation》

静态库和动态库
![[binocular vision] binocular correction](/img/fe/27fda48c36ca529eec21c631737526.png)
[binocular vision] binocular correction
利用超球嵌入来增强对抗训练
随机推荐
Correction binoculaire
E-R draw clear content
Deep learning classification Optimization Practice
Business architecture diagram
【Batch】learning notes
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
In the era of short video, how to ensure that works are more popular?
Meta Learning 简述
Feature Engineering: summary of common feature transformation methods
Open3d learning notes II [file reading and writing]
【FastDepth】《FastDepth:Fast Monocular Depth Estimation on Embedded Systems》
【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
CVPR19-Deep Stacked Hierarchical Multi-patch Network for Image Deblurring论文复现
Label propagation
Eklavya -- infer the parameters of functions in binary files using neural network
【TCDCN】《Facial landmark detection by deep multi-task learning》
Command line is too long
联邦学习下的数据逆向攻击 -- GradInversion
[learning notes] matlab self compiled Gaussian smoother +sobel operator derivation
Organigramme des activités