当前位置:网站首页>【统计学习方法】学习笔记——支持向量机(上)
【统计学习方法】学习笔记——支持向量机(上)
2022-07-07 10:28:00 【镰刀韭菜】
统计学习方法学习笔记——支持向量机(上)
支持向量机(support vector machines, SVM)是 一种二类分类模型。它的基本模型是 定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;支持向量机还包括 核技巧,这使它成为实质上的 非线性分类器。 支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadratic programming)的问题,也等价于正则化的合页损失函数的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
支持向量机学习方法包含构建由简至繁的模型:
- 线性可分SVM:当训练数据线性可分时,通过
硬间隔最大化,学习一个线性的分类器,即线性可分SVM,又称硬间隔SVM。 - 线性SVM:当训练数据近似线性可分时,通过
软间隔最大化,也学习一个线性分类器,即线性SVM,又称软间隔SVM。 - 非线性SVM:当训练数据线性不可分时,通过使用
核技巧及软间隔最大化,学习非线性SVM。
核函数表示将输入从输入空间映射到特征空间得到特征向量之间的内积。通过使用核函数可以学习非线性SVM,等价于隐式地在高维特征空间中学习线性SVM。这样的方法称为核方法,核方法是比SVM更为一般的机器学习方法。
1. 线性可分支持向量机与硬间隔最大化
1.1 线性可分支持向量机
假设输入空间为欧氏空间或离散集合,特征空间为欧氏空间或希尔伯特空间。线性可分支持向量机、线性支持向量机假设这两个空间的元素一一对应,并将输入空间中的输入映射为特征空间中的特征向量。
非线性支持向量机利用一个从输入空间到特征空间的非线性映射将输入映射为特征向量。所以,输入都由输入空间转换到特征空间,支持向量机的学习是在特征空间进行的。
假设给定一个特征空间上的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn, y i ∈ y = { + 1 , − 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{+1, -1\}, i=1,2,..., N yi∈y={ +1,−1},i=1,2,...,N。 x i x_i xi为第 i i i个特征向量,也成为实例。 y i y_i yi为 x i x_i xi的类标记。当 y i = + 1 y_i=+1 yi=+1时,称 x i x_i xi为正例;当 y i = − 1 y_i=-1 yi=−1时,称 x i x_i xi为负例。 ( x i , y i ) (x_i, y_i) (xi,yi)为样本点。再假设训练数据集是线性可分的。
学习的目标是在特征空间中找到一个分离超平面,能将实例分到不同的类。分离超平面对应于方程 w ⋅ x + b = 0 w\cdot x + b=0 w⋅x+b=0,它由法向量 w w w和截距 b b b决定,可用 ( w , b ) (w,b) (w,b)来表示。分离超平面将特征空间划分为两部分,一部分是正类,一部分是负类。法向量指向的是一侧为正类,另一侧为负类。
一般地,当训练数据集线性可分时,存在无穷个分离超平面可将两类数据正确分类。感知机利用误分类最小的策略,求得分离超平面,但是这时的解有无穷多个。而线性可分支持向量机就是找到最大的间隔分离超平面,这是唯一的。
1.2 函数间隔和几何间隔
一般来说,一个点距离分离超平面的远近可以表示分类预测的确信程度。在超平面 w ⋅ x + b = 0 w\cdot x + b =0 w⋅x+b=0确定的情况下, ∣ w ⋅ x + b ∣ |w\cdot x +b| ∣w⋅x+b∣能够相对地表示点 x x x距离超平面的远近,而 w ⋅ x + b w\cdot x +b w⋅x+b的符号与类标记 y y y的符号是否一致能够表示分类是否正确。所以可用量 y ( w ⋅ x + b ) y(w\cdot x +b) y(w⋅x+b)来表示分类的正确性及确信度。这就是函数间隔(functional margin)的概念。
函数间隔可以表示分类预测的正确性及确信度。但是如果成比例地改变 w w w和 b b b,超平面并没有改变,但是函数间隔却成为原来的2倍。
为了保证唯一性,可以对分离超平面法向量 w w w加某些约束,如规范化, ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1,这使得间隔是确定的。这时函数间隔成为几何间隔(geometric margin)。
一般地,当样本点 ( x i , y i ) (x_i, y_i) (xi,yi)被超平面 ( w , b ) (w, b) (w,b)正确分类时,点 x i x_i xi与超平面 ( w , b ) (w, b) (w,b)的距离是
γ i = y i ( w ∣ ∣ w ∣ ∣ ⋅ x i + b ∣ ∣ w ∣ ∣ ) \gamma_i=y_i(\frac{w}{||w||} \cdot x_i + \frac{b}{||w||}) γi=yi(∣∣w∣∣w⋅xi+∣∣w∣∣b)
由这一事实导出几何间隔的概念。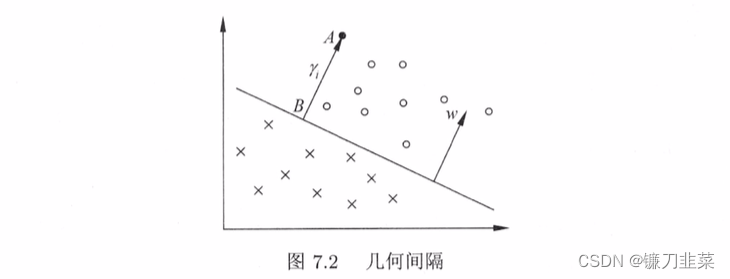

从函数间隔和几何间隔的定义可知,函数间隔和几何间隔有下面的关系: γ i = γ ^ i ∣ ∣ w ∣ ∣ \gamma_i=\frac{\hat{\gamma}_i}{||w||} γi=∣∣w∣∣γ^i γ = γ ^ ∣ ∣ w ∣ ∣ \gamma = \frac{\hat{\gamma}}{||w||} γ=∣∣w∣∣γ^如果 ∣ ∣ w ∣ ∣ = 1 ||w||=1 ∣∣w∣∣=1,那么函数间隔和几何间隔相等。如果超平面参数 w w w和 b b b成比例地改变(超平面没有改变),函数间隔也按此比例改变,而几何间隔不变。
1.3 间隔最大化
支持向量机学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。对线性可分的训练集而言,线性可分离超平面有无穷多个(等价于感知机),但是几何间隔最大的分离超平面是唯一的。这里的间隔最大化又称为硬间隔最大化(与将要讨论的训练数据集近似线性可分时的软间隔最大化相对应)。
间隔最大化:对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。也就是说不仅将正负实例点分开,而且对难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。
- 最大间隔分离超平面
下面考虑如何求得一个几何间隔最大的分离超平面,即最大间隔分离超平面。具体地,这个问题可以表示为下面的约束最优化问题
max w , b γ \max_{w,b} \gamma w,bmaxγ s . t . y i ( w ∣ ∣ w ∣ ∣ ⋅ x i + b ∣ ∣ w ∣ ∣ ) ≥ γ , i = 1 , 2 , . . . , N s.t. \ y_i(\frac{w}{||w||}\cdot x_i+\frac{b}{||w||})\ge \gamma, i=1,2,...,N s.t. yi(∣∣w∣∣w⋅xi+∣∣w∣∣b)≥γ,i=1,2,...,N
即我们希望最大化超平面 ( w , b ) (w,b) (w,b)关于训练数据集的几何间隔 γ \gamma γ,约束条件表示的是超平面 ( w , b ) (w,b) (w,b)关于每个训练样本点的几何间隔至少是 γ \gamma γ。
考虑几何间隔和函数间隔的关系式 γ = γ ^ ∣ ∣ w ∣ ∣ \gamma = \frac{\hat{\gamma}}{||w||} γ=∣∣w∣∣γ^,可将问题改写成
max w , b γ ^ ∣ ∣ w ∣ ∣ \max_{w,b} \frac{\hat{\gamma}}{||w||} w,bmax∣∣w∣∣γ^ s . t . y i ( w ⋅ x i + b ) ≥ γ ^ , i = 1 , 2 , . . . , N s.t. y_i(w\cdot x_i+b)\ge \hat{\gamma}, i=1,2,...,N s.t.yi(w⋅xi+b)≥γ^,i=1,2,...,N
函数间隔 γ \gamma γ的取值并不影响最优化问题的解。假设将 w w w和 b b b按比例改变为 λ w \lambda w λw和KaTeX parse error: Undefined control sequence: \lambdab at position 1: \̲l̲a̲m̲b̲d̲a̲b̲,这时函数间隔称为 λ γ ^ \lambda \hat{\gamma} λγ^,函数间隔的这一改变对上面最优化问题的不等式约束没有影响,对目标函数的优化也没有影响。这样,就可以取 γ ^ = 1 \hat{\gamma} = 1 γ^=1。
又注意到最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1和最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2是等价的,于是得到下面的最优化问题
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 \min_{w,b} \frac{1}{2}||w||^2 w,bmin21∣∣w∣∣2 s . t . y i ( w ⋅ x i + b ) − 1 ⩾ 0 , i = 1 , 2 , . . . , N s.t. y_i(w\cdot x_i+b)−1⩾0, i=1,2,...,N s.t.yi(w⋅xi+b)−1⩾0,i=1,2,...,N
这是一个凸二次规划(convex quadratic programming)问题。
求解约束最优化问题,得到 w ∗ w∗ w∗和 b ∗ b∗ b∗,就可以得到最大间隔分离超平面 w ∗ ⋅ x + b ∗ = 0 w^* \cdot x + b^* = 0 w∗⋅x+b∗=0以及分类决策函数 f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x) = sign(w^* \cdot x + b^*) f(x)=sign(w∗⋅x+b∗),即线性可分支持向量机模型。
算法:线性可分支持向量机学习算法——最大间隔法
输入:线性可分训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn, y i ∈ y = { + 1 , − 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{+1, -1\}, i=1,2,..., N yi∈y={ +1,−1},i=1,2,...,N;
输出:最大间隔分离超平面和分类决策函数.
(1)构造并求解约束最优化问题: min w , b 1 2 ∣ ∣ w ∣ ∣ 2 \min_{w, b} \ \frac{1}{2}||w||^2 w,bmin 21∣∣w∣∣2 s . t . y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , . . . , N s.t. \ y_i(w\cdot x_i + b)-1 \ge 0, i=1,2, ..., N s.t. yi(w⋅xi+b)−1≥0,i=1,2,...,N
求得最优解 w ∗ , b ∗ w^*, b^* w∗,b∗
(2)由此得到分离超平面: w ∗ ⋅ x + b ∗ = 0 w^* \cdot x + b^* = 0 w∗⋅x+b∗=0分类决策函数 f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign (w^* \cdot x + b^*) f(x)=sign(w∗⋅x+b∗)
最大间隔分离超平面的存在唯一性
线性可分训练数据集的最大间隔分离超平面是存在且唯一的。
定理(最大间隔分离超平面的存在唯一性):若训练数据集T线性可分,则可将训练数据集中的样本点完全正确分类的最大间隔分离超平面存在且唯一。支持向量和间隔边界
在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量(support vector)。支持向量是使下式等号成立的点,即 y i ( w ⋅ x i + b ) − 1 = 0 y_i(w\cdot x_i + b)-1=0 yi(w⋅xi+b)−1=0
对 y i = + 1 y_i=+1 yi=+1的正例点,支持向量在超平面 H 1 : w ⋅ x + b = 1 H_1: w\cdot x + b = 1 H1:w⋅x+b=1上,对 y i = − 1 y_i=-1 yi=−1的负例点,支持向量在超平面 H 2 : w ⋅ + b = − 1 H_2: w\cdot +b = -1 H2:w⋅+b=−1上。如图7.3所示,在 H 1 H_1 H1和 H 2 H_2 H2上的点就是支持向量。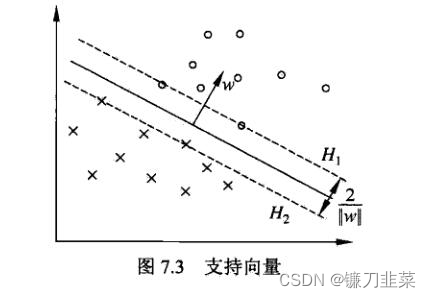
间隔边界: H 1 H_1 H1和 H 2 H_2 H2平行,并没有实例点落在它们中间。 H 1 H_1 H1与 H 2 H_2 H2之间形成一条长带,分离超平面与它们平行且位于它们中央。长度的宽度,即 H 1 H_1 H1和 H 2 H_2 H2之间的距离称为间隔,间隔依赖于分离超平面的法向量 w w w,等于 2 ∣ ∣ w ∣ ∣ 2||w|| 2∣∣w∣∣, H 1 H_1 H1和 H 2 H_2 H2称为间隔边界。
在决定分离超平面时,只有支持向量起作用。如果移动支持向量将改变所求的解,但是如果在间隔边界以外移动其它实例点,甚至去掉这些点,解都不会改变。
由于支持向量在确定超平面中起着决定性作用,所以这个方法称为支持向量机。支持向量的个数一般很少,所以支持向量机由很少的“重要”训练样本确定。
1.4 学习的对偶算法
对偶算法(dual algorithm):为了求线性可分支持向量机的最优化问题,将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶(dual problem)问题得到原始问题(primal problem)的最优解。这样做的优点:一是对偶问题往往更容易求解;二是自然引入核函数,进而推广到非线性分类问题。
首先,构建拉格朗日函数(Lagrange function)。为此,对每一个不等式约束引进拉格朗日乘子(lagrange multiplier) α i ≥ 0 , i = 1 , 2 , . . . , N \alpha_i \ge 0, i=1,2,...,N αi≥0,i=1,2,...,N,定义拉格朗日函数:
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i y i ( w ⋅ x i + b ) + ∑ i = 1 N α i L(w, b, \alpha)=\frac{1}{2}||w||^2 - \sum_{i=1}^N \alpha_i y_i(w\cdot x_i + b)+\sum_{i=1}^N \alpha_i L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi其中 α = ( α 1 , α 2 , . . . , α N ) T \alpha = (\alpha_1, \alpha_2,...,\alpha_N)^T α=(α1,α2,...,αN)T为拉格朗日乘子向量。
根据拉格朗日对偶性,原始问题的对偶问题使极大极小问题: max α min w , b L ( w , b , α ) \max_{\alpha}\min_{w,b} L(w, b,\alpha) αmaxw,bminL(w,b,α)
所以,为了得到对偶问题的解,需要先求 L ( w , b , α ) L(w, b, \alpha) L(w,b,α)对 w , b w,b w,b的极小,再求对 α \alpha α的极大。
(1)求 min w , b L ( w , b , α ) \min_{w,b} L(w,b,\alpha) minw,bL(w,b,α)
将拉格朗日函数 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)分别对 w , b w,b w,b求偏导数并令其等于0.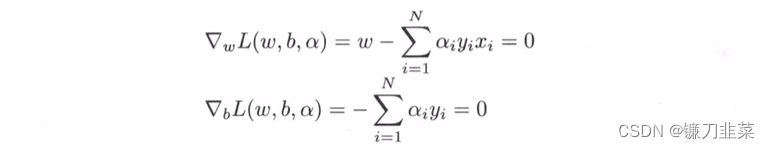
得: w = ∑ i = 1 N α i y i x i w = \sum_{i=1}^N \alpha_i y_i x_i w=i=1∑Nαiyixi ∑ i = 1 N α i y i = 0 \sum_{i=1}^N \alpha_i y_i =0 i=1∑Nαiyi=0
将其带入拉格朗日函数中,即得: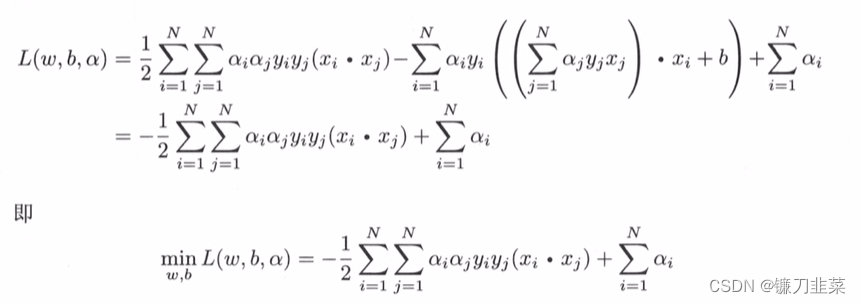
(2)求 min w , b L ( w , b , α ) \min_{w,b} L(w,b, \alpha) minw,bL(w,b,α)对 α \alpha α的极大,即是对偶问题。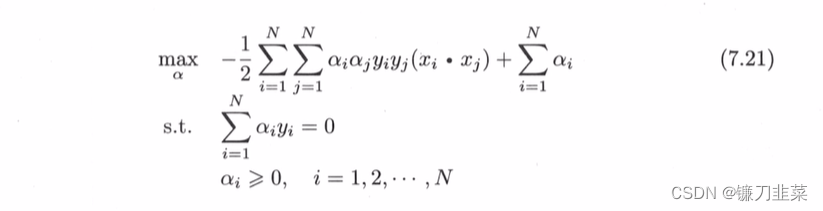
将上式的目标函数由求极大转换为求极小,就得到了下面与之等价的对偶最优化问题: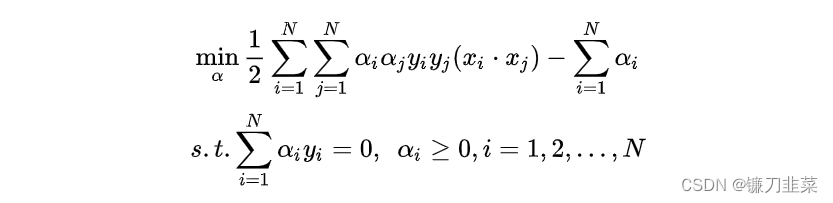

通过KKT条件解对偶问题可得:
w ∗ = ∑ i = 1 N α i ∗ y i ∗ x i ∗ w^* = \sum_{i=1}^N \alpha_i^*y_i^*x_i^* w∗=i=1∑Nαi∗yi∗xi∗ b ∗ = y j − ∑ i = 1 N α i ∗ y i ( x i ⋅ x j ) b^*=y_j-\sum_{i=1}^N\alpha_i^*y_i(x_i\cdot x_j) b∗=yj−i=1∑Nαi∗yi(xi⋅xj)
由此定理可知,分离超平面可以写成 ∑ i = 1 N α i ∗ y i ( x ⋅ x i ) + b ∗ = 0 \sum_{i=1}^N \alpha_i^* y_i(x\cdot x_i)+b^*=0 i=1∑Nαi∗yi(x⋅xi)+b∗=0
分类决策函数可以写成 f ( x ) = s i g n { ∑ i = 1 N α i ∗ y i ( x ⋅ x i ) + b ∗ } f(x)=sign\{\sum_{i=1}^N \alpha_i^* y_i(x\cdot x_i)+b^*\} f(x)=sign{ i=1∑Nαi∗yi(x⋅xi)+b∗}
这就是说,分类决策函数只依赖于输入x和训练样本输入的内积。上式称为线性可分支持向量机的对偶形式。
算法:线性可分支持向量机学习算法
输入:线性可分训练数据集 T = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)} T=(x1,y1),(x2,y2),...,(xN,yN),其中, x i ∈ X = R n , y i ∈ Y = { − 1 , + 1 } , i = 1 , 2 , . . . , N x_i\in \mathcal{X}=R^n,y_i \in \mathcal{Y}=\{−1,+1\},i=1,2,...,N xi∈X=Rn,yi∈Y={ −1,+1},i=1,2,...,N;
输出:最大间隔分离超平面和分类决策函数。
(1)构造并求解约束最优化问题:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i \min_α \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i\alpha_jy_iy_j(x_i\cdot x_j)−\sum_{i=1}^N \alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi s . t . ∑ i = 1 N α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . , N s.t.\ \sum_{i=1}^N \alpha_iy_i=0, \ \alpha_i\ge 0,i=1,2,...,N s.t. i=1∑Nαiyi=0, αi≥0,i=1,2,...,N
求得最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^∗=(\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T;
(2)计算:
w ∗ = ∑ i = 1 N α i ∗ y i x i w^∗=\sum_{i=1}^N \alpha_i^* y_ix_i w∗=i=1∑Nαi∗yixi
并选择 α ∗ \alpha^∗ α∗的一个正分量 α j ∗ > 0 \alpha_j^*>0 αj∗>0,计算:
b ∗ = y j − ∑ i = 1 N α i ∗ y i ( x i ⋅ x j ) b^∗=y_j−\sum_{i=1}^N\alpha_i^*y_i(x_i\cdot x_j) b∗=yj−i=1∑Nαi∗yi(xi⋅xj)
(3)求得分离超平面:
w ∗ ⋅ x + b ∗ = 0 w^* \cdot x +b^* = 0 w∗⋅x+b∗=0
分类决策函数:
f ( x ) = s i g n { w ∗ ⋅ x + b ∗ } f(x)=sign\{w^* \cdot x + b^*\} f(x)=sign{ w∗⋅x+b∗}
定义:支持向量:考虑原始最优化问题及对偶最优化问题,将训练数据集中对应于 α i ∗ > 0 \alpha_i^* >0 αi∗>0的样本点 ( x i , y i ) (x_i, y_i) (xi,yi)的实例 x i ∈ R n x_i \in R^n xi∈Rn称为支持向量。
2. 线性支持向量机与软间隔最大化
2.1 线性支持向量机
线性可分问题的支持向量机学习方法,对线性不可分训练集数据是不适用的,因为这时上述方法中的不等式约束并不能都成立。怎么才能将它扩展到线性不可分问题呢?这就需要修改硬间隔最大化,使其成为软间隔最大化。
假设给定一个特征空间上的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn, y i ∈ y = { + 1 , − 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{+1, -1\}, i=1,2,..., N yi∈y={ +1,−1},i=1,2,...,N。 x i x_i xi为第 i i i个特征向量,也成为实例。 y i y_i yi为 x i x_i xi的类标记。通常情况是,训练数据中有一些特异点(outlier)。将这些特异点除去后,剩下大部分的样本点组成的集合是线性可分的。
线性不可分意味着某些样本点 ( x i , y i ) (x_i,y_i) (xi,yi)不能满足函数间隔大于等于1的约束条件(7.14)。为了解决这个问题,可以对每个样本点 ( x i , y i ) (x_i,y_i) (xi,yi)引入一个松弛变量 ξ i ⩾ 0 ξ_i⩾0 ξi⩾0,使函数间隔加上松弛变量大于等于1。这样,约束条件变成
y i ( w ⋅ x i + b ) ⩾ 1 − ξ i y_i(w\cdot x_i+b)⩾1−ξ_i yi(w⋅xi+b)⩾1−ξi
同时对每个松弛变量 ξ i ξ_i ξi支付一个代价,目标函数变成
1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \frac{1}{2}||w||^2+C\sum_{i=1}^Nξ_i 21∣∣w∣∣2+Ci=1∑Nξi
这里 C > 0 C>0 C>0称为惩罚参数,一般由应用问题决定,C值大时对误分类的惩罚增大,C值小时对误分类的惩罚减小。
最小化目标函数包含两层含义:使 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2尽量小即间隔尽量大,同时使误分类点的个数尽量小,C是调和二者的系数。
学习问题:线性不可分的支持向量机的学习问题变成如下凸二次规划问题
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \min_{w,b,ξ} \frac{1}{2}||w||^2 + C\sum_{i=1}^N ξ_i w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξi
s . t . y i ( w ⋅ x i + b ) ⩾ 1 − ξ i , i = 1 , 2 , . . . , N s.t. y_i(w\cdot x_i + b)⩾1−ξ_i, i=1,2,...,N s.t.yi(w⋅xi+b)⩾1−ξi,i=1,2,...,N
ξ i ⩾ 0 , i = 1 , 2 , . . . , N ξ_i⩾0, i=1,2,...,N ξi⩾0,i=1,2,...,N
可以证明w的解是唯一的,但b的解可能不唯一,而是存在于一个区间。
设上述问题的解是 w ∗ , b ∗ w^∗,b^∗ w∗,b∗,于是可以得到分离超平面 w ∗ ⋅ x + b ∗ = 0 w^∗\cdot x+b^∗=0 w∗⋅x+b∗=0及分类决策函数 f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(w^∗\cdot x+b^∗) f(x)=sign(w∗⋅x+b∗)。称这样的模型为训练样本线性不可分时的线性支持向量机,简称线性SVM。显然线性SVM包含线性可分SVM。由于现实中训练数据集往往是线性不可分的,线性SVM具有更广的适用性。
定义:线性支持向量机 对于给定的线性不可分的训练数据集,通过求解凸二次规划问题,即软间隔最大化问题,得到的分离超平面为 w ∗ ⋅ x + b ∗ = 0 w^∗\cdot x+b^∗=0 w∗⋅x+b∗=0以及相应的分类决策函数 f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(w^∗\cdot x+b^∗) f(x)=sign(w∗⋅x+b∗)称为线性支持向量机.
2.2 学习的对偶算法
算法:线性支持向量机学习算法
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1, y_1), (x_2, y_2), ..., (x_N, y_N)\} T={ (x1,y1),(x2,y2),...,(xN,yN)},其中 x i ∈ X = R n x_i\in \mathcal{X}=R^n xi∈X=Rn, y i ∈ y = { + 1 , − 1 } , i = 1 , 2 , . . . , N y_i\in \mathcal{y}=\{+1, -1\}, i=1,2,..., N yi∈y={ +1,−1},i=1,2,...,N;
输出:分离超平面和分类决策函数。
(1)选择惩罚参数 C > 0 C>0 C>0,构造并求解凸二次规划问题
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i \min_\alpha \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum_{i=1}^N \alpha_i αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
s . t . ∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N s.t. \ \sum_{i=1}^N \alpha_i y_i = 0, 0\le \alpha_i \le C, i=1,2,..., N s.t. i=1∑Nαiyi=0,0≤αi≤C,i=1,2,...,N
求得最优解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*, \alpha_2^*, ..., \alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T。
(2)计算 w ∗ = ∑ i = 1 N α i ∗ y i x i w^*=\sum_{i=1}^N \alpha_i^* y_i x_i w∗=∑i=1Nαi∗yixi
选择 α ∗ \alpha^* α∗的一个分量 α j ∗ \alpha_j^* αj∗适合条件 0 < α j ∗ < C 0< \alpha_j^* < C 0<αj∗<C,计算 b ∗ = y j − ∑ i = 1 N y i α i ∗ ( x i ⋅ x j ) b^*=y^j-\sum_{i=1}^Ny_i\alpha_i^*(x_i \cdot x_j) b∗=yj−∑i=1Nyiαi∗(xi⋅xj)
(3)求得分离超平面
w ∗ ⋅ x + b ∗ = 0 w^* \cdot x + b^* = 0 w∗⋅x+b∗=0
分类决策函数: f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(w^* \cdot x + b^*) f(x)=sign(w∗⋅x+b∗)
2.3 支持向量
这里的支持向量是软分隔情况下的支持向量。在线性不可分的情况下,将对偶问题的解 α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*, \alpha_2^*, ..., \alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T中对应于 α i ∗ > 0 \alpha_i^*>0 αi∗>0的样本点 ( x i , y i ) (x_i,y_i) (xi,yi)的实例 x i x_i xi称为支持向量(软间隔的支持向量)。如下图所示,这时的支持向量要比线性可分时的情况复杂一些。图中还标出了实例 x i x_i xi到间隔边界的距离 ξ i ∣ ∣ w ∣ ∣ \frac{ξ_i}{||w||} ∣∣w∣∣ξi。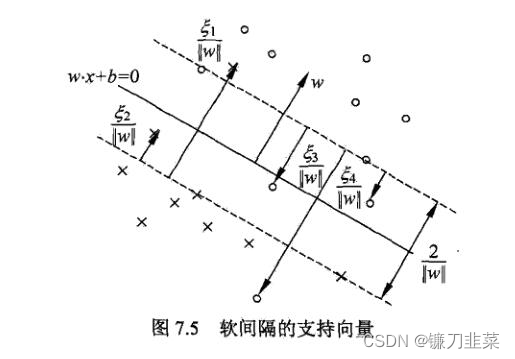
软间隔的支持向量 x i x_i xi或者在间隔边界上,或者在间隔边界与分离超平面之间,或者在分离超平面误分一侧。
- 若 α i ∗ < C \alpha_i^*<C αi∗<C,则 ξ i = 0 ξ_i=0 ξi=0,支持向量 x i x_i xi恰好落在间隔边界上。
- 若 α i ∗ = C \alpha_i^*=C αi∗=C, 0 < ξ i < 1 0<ξ_i<1 0<ξi<1,则分类正确, x i x_i xi在间隔边界与分离超平面之间。
- 若 α i ∗ = C \alpha_i^*=C αi∗=C, ξ i = 1 ξ_i=1 ξi=1,则分类正确, x i x_i xi在间隔边界与分离超平面之间。
- 若 α i ∗ = C \alpha_i^*=C αi∗=C, ξ i > 1 ξ_i>1 ξi>1,则 x i x_i xi位于分离超平面误分一侧。
2.4 合页损失函数
对于线性支持向量机学习来说,其模型为分离超平面 w ∗ ⋅ x + b ∗ = 0 w^* \cdot x + b^*=0 w∗⋅x+b∗=0及决策函数 f ( x ) = s i g n ( w ∗ ⋅ x + b ∗ ) f(x)=sign(w^* \cdot x + b^*) f(x)=sign(w∗⋅x+b∗),其学习策略为软间隔最大化,学习算法为凸二次规划。
损失函数的说明:线性SVM学习还有另一种解释,就是最小化以下目标函数:
∑ i = 1 N [ 1 − y i ( w ⋅ x i + b ) ] + + λ ∣ ∣ w ∣ ∣ 2 \sum_{i=1}^N[1−y_i(w\cdot x_i+b)]_++λ||w||^2 i=1∑N[1−yi(w⋅xi+b)]++λ∣∣w∣∣2
目标函数的第1项是经验风险,函数 L ( y ( w ⋅ x + b ) ) = [ 1 − y ( w ⋅ x + b ) ] + L(y(w\cdot x+b))=[1−y(w\cdot x+b)]_+ L(y(w⋅x+b))=[1−y(w⋅x+b)]+称为合页损失函数(hinge loss),下标“+”表示以下取正值的函数
[ z ] + = { z , z > 0 0 , z ≤ 0 [z]_+=\left\{\begin{matrix} z, & z>0\\ 0, & z\le 0 \end{matrix}\right. [z]+={ z,0,z>0z≤0
这就是说,当样本点 ( x i , y i ) (x_i,y_i) (xi,yi)被正确分类且函数间隔(确信度) y i ( w ⋅ x i + b ) y_i(w\cdot x_i+b) yi(w⋅xi+b)大于1时,损失是0,否则损失是 1 − y i ( w ⋅ x i + b ) 1−y_i(w\cdot x_i+b) 1−yi(w⋅xi+b)。
目标函数的第2项是系数为 λ λ λ的w的 L 2 L_2 L2范数,是正则化项。
定理: 线性支持向量机原始最优化问题:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ξ i \min_{w,b,ξ} \frac{1}{2}||w||^2 + C\sum_{i=1}^N ξ_i w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξi
s . t . y i ( w ⋅ x i + b ) ⩾ 1 − ξ i , i = 1 , 2 , . . . , N s.t. y_i(w\cdot x_i + b)⩾1−ξ_i, i=1,2,...,N s.t.yi(w⋅xi+b)⩾1−ξi,i=1,2,...,N
ξ i ⩾ 0 , i = 1 , 2 , . . . , N ξ_i⩾0, i=1,2,...,N ξi⩾0,i=1,2,...,N
等价于最优化问题 min w , b ∑ i = 1 N [ 1 − y i ( w ⋅ x i + b ) ] + + λ ∣ ∣ w ∣ ∣ 2 \min_{w,b} \sum_{i=1}^N[1−y_i(w\cdot x_i+b)]_++λ||w||^2 w,bmini=1∑N[1−yi(w⋅xi+b)]++λ∣∣w∣∣2.
合页损失函数的图形如下图所示,横轴是函数间隔 y ( w ⋅ x + b ) y(w\cdot x + b) y(w⋅x+b),纵轴是损失。由于函数形状像一个合页,故名合页损失函数。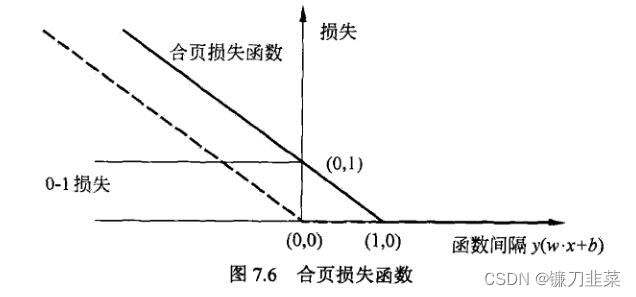
图中还画出0-1损失函数,可以认为它是二分类问题的真正损失函数,而合页损失函数是0-1损失函数的上界。由于0-1损失不是连续可导的,直接优化比较困难,可以认为线性SVM是优化0-1损失的上界(合页损失)构成的目标函数。这时的上界损失又称为代理损失函数(surrogate loss function)。
图中虚线显示的是感知机的损失 [ − y i ( w ⋅ x i ) + b ] + [−y_i(w\cdot x_i)+b]_+ [−yi(w⋅xi)+b]+。样本被正确分类时损失为0,否则为 − y i ( w ⋅ x i ) + b −y_i(w\cdot x_i)+b −yi(w⋅xi)+b。相比之下,合页损失不仅要分类正确,而且要确信度高,损失才是0,也就是说合页损失函数对学习有更高的要求。
内容来源:
[1] 《统计学习方法》李航
[2] https://www.cnblogs.com/liaohuiqiang/p/10980066.html
边栏推荐
- 平安证券手机行开户安全吗?
- Will the filing free server affect the ranking and weight of the website?
- Experiment with a web server that configures its own content
- Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
- Minimalist movie website
- NGUI-UILabel
- 编译 libssl 报错
- 《通信软件开发与应用》课程结业报告
- 百度数字人度晓晓在线回应网友喊话 应战上海高考英语作文
- EPP+DIS学习之路(2)——Blink!闪烁!
猜你喜欢
Introduction and application of smoothstep in unity: optimization of dissolution effect
SQL Lab (46~53) (continuous update later) order by injection

Completion report of communication software development and Application

Rationaldmis2022 array workpiece measurement

Sonar:cognitive complexity
MATLAB實現Huffman編碼譯碼含GUI界面
什么是ESP/MSR 分区,如何建立ESP/MSR 分区
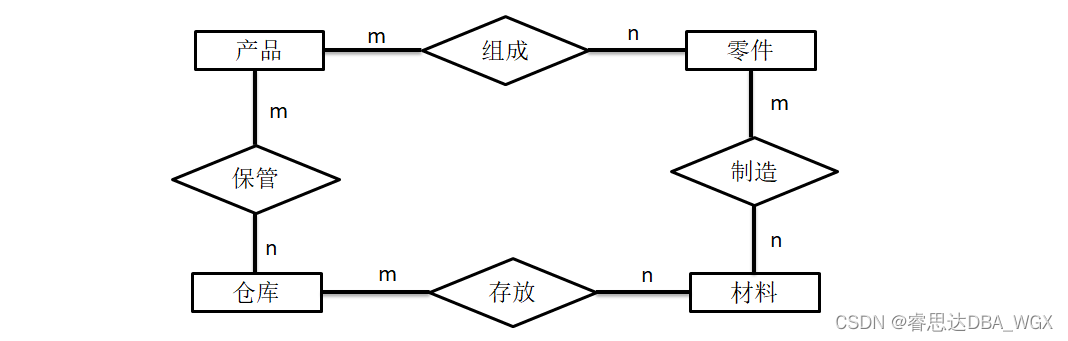
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
从工具升级为解决方案,有赞的新站位指向新价值
EPP+DIS学习之路(2)——Blink!闪烁!
随机推荐
Is it safe to open an account in Ping An Securities mobile bank?
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
Processing strategy of message queue message loss and repeated message sending
Epp+dis learning path (1) -- Hello world!
H3C HCl MPLS layer 2 dedicated line experiment
Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
The road to success in R & D efficiency of 1000 person Internet companies
数据库系统原理与应用教程(008)—— 数据库相关概念练习题
sql-lab (54-65)
<No. 8> 1816. 截断句子 (简单)
数据库系统原理与应用教程(011)—— 关系数据库
Minimalist movie website
Xiaohongshu microservice framework and governance and other cloud native business architecture evolution cases
Cenos openssh upgrade to version 8.4
SQL lab 1~10 summary (subsequent continuous update)
Attack and defense world ----- summary of web knowledge points
百度数字人度晓晓在线回应网友喊话 应战上海高考英语作文
Up meta - Web3.0 world innovative meta universe financial agreement
解决 Server returns invalid timezone. Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
【玩转 RT-Thread】 RT-Thread Studio —— 按键控制电机正反转、蜂鸣器