当前位置:网站首页>Wu Enda's latest interview! Data centric reasons
Wu Enda's latest interview! Data centric reasons
2022-07-06 14:21:00 【Datawhale】
Datawhale dried food
compile : Victor 、 Wang Ye , source :AI Technology Review

Wu Enda is an AI (AI) And one of the most authoritative international scholars in the field of machine learning , In the last year , He's been talking about “ Data centric AI”, I hope to shift everyone's attention from model centered to data centered .
lately , In an interview with IEEE Spectrum Interview , He talked about the basic model 、 big data 、 Some insights on small data and data engineering , And the initiation “ Data centric AI” The reason for the movement .
“ Over the past decade , Code — The architecture of neural network has been very mature . Keep the neural network architecture fixed , Find ways to improve data , Will be more efficient .”
Wu said , His data centric thinking has received a lot of criticism , Just like when he initiated Google brain project , Support the construction of large-scale neural network actions , It's the same when you're criticized : The idea is not new , Wrong direction . According to Professor Wu , Among the critics are industry veterans .
About small data , Professor Wu believes that , It can also be powerful :“ As long as you have 50 Good data (examples), It's enough to explain to the neural network what you want it to learn .”
The following is the original interview ,AI The science and Technology Review compiled without changing its original meaning .

IEEE: Over the past decade , The success of deep learning comes from big data and big models , But some people think this is an unsustainable path , Do you agree with this view ?
Wu enda : Good question .
We are already in natural language processing (NLP) The domain sees the basic model (foundation models) The power of . Tell the truth , I'm interested in the bigger NLP Model , And in computer vision (CV) Excited about building a basic model in . There is a lot of information in video data that can be used , However, due to the limitation of computing performance and video data processing cost , It is not possible to establish the relevant basic model .
Big data and big model have been successfully run as a deep learning engine 15 year , It's still alive . That being the case , But in some cases , We also see , Big data doesn't apply ,“ Little data ” Is a better solution .
IEEE: What you mentioned CV What does the basic model mean ?
Wu enda : It means very large , And train the model on big data , When using, you can fine tune for specific applications . It's a term I created with my friends at Stanford , for example GPT-3 Namely NLP The basic model of the domain . The basic model provides a new paradigm for developing machine learning applications , There are great prospects , But there are also challenges : How to ensure reasonable 、 fair 、 Unbiased ? These challenges as more and more people build applications based on basic models , It will become more and more obvious .
IEEE: by CV Where is the opportunity to create the basic model ?
Wu enda : There are still scalability challenges . comparison NLP,CV Need more computing power . If we can produce higher than now 10 Times the performance of the processor , It's very easy to build a database that contains 10 Basic visual model of multiple video data . at present , Has appeared in CV Signs of developing basic models in .
Speaking of this , Let me mention : Over the past decade , The success of deep learning occurs more in consumer oriented companies , These companies are characterized by huge user data . therefore , In other industries , Deep learning “ Scale paradigm ” Not applicable .
IEEE: I remember when you said that , You were in a consumer oriented company in the early days , With millions of users .
Wu enda : Ten years ago , When I initiate Google Brain project , And use Google Computing infrastructure construction “ Big ” When it comes to neural networks , It caused a lot of controversy . At that time, there was an industry veteran ,“ quietly ” Tell me : start-up Google Brain The project is not conducive to my career , I shouldn't just focus on large-scale , Instead, focus on architectural innovation .
I still remember , The first article published by me and my students NeurIPS workshop The paper , Advocate the use of CUDA. But another industry veteran advised me :CUDA Programming is too complicated , Take it as a programming paradigm , It's too much work . I tried to persuade him , But I failed .
IEEE: I think now they've been convinced .
Wu enda : Yes, I think it is .
In the past year , I've been talking about data centric AI, I met and 10 The same evaluation as years ago :“ Nothing new ”,“ This is the wrong direction ”.
IEEE: How do you define “ Data centric AI”, Why call it a sport ?
Wu enda :“ Data centric AI” It is a systematic discipline , It aims to focus on building AI The data required by the system . about AI System , Implement the algorithm with code , Then training on the data set is very necessary . Over the past decade , People have been following “ Download datasets , Improve the code ” This paradigm , Thanks to this paradigm , Deep learning has been a great success .
But for many applications , Code — Neural network architecture , It has been basically solved , It won't be a big difficulty . Therefore, keep the neural network architecture fixed , Find ways to improve data , Will be more efficient .
When I first mentioned it , Many people also raised their hands in favor of : We have followed “ tricks ” Did 20 year , I've been doing things by intuition , It's time to turn it into a systematic engineering discipline .
“ Data centric AI” Much larger than a company or a group of researchers . When I was with my friends NeurIPS Organized a “ Data centric AI” During the Seminar , I am very pleased with the number of authors and speakers present .
IEEE: Most companies only need a small amount of data , that “ Data centric AI” How to help them ?
Wu enda : I used to use 3.5 Billion images to build a human face recognition system , You may also often hear stories about building visual systems with millions of images . But the architecture under these scale products , You can't just 50 Design of a picture construction system . The fact proved that . If all you have is 50 A high quality picture , Can still produce very valuable things , For example, defect system detection . In many industries , Big data sets don't exist , therefore , I think we must focus on “ Move from big data to high-quality data ”. Actually , As long as you have 50 Good data (examples), It's enough to explain to the neural network what you want it to learn .
Wu enda : Use 50 What kind of model does this picture train ? Is to fine tune the big model , Or a new model ?
Wu enda : Let me talk about Landing AI The job of . When doing visual inspection for the manufacturer , We often use training models ,RetinaNet, Pre training is only a small part of it . The more difficult problem is to provide tools , Enable the manufacturer to select and mark the correct image set for fine tuning in the same way . This is a very practical problem , Whether in vision 、NLP, Or voice field , Even the marking staff are unwilling to mark manually . When using big data , If the data is uneven , The common way to deal with it is to get a lot of data , Then the algorithm is used for average processing . however , If we can develop some tools to mark the differences of data , And provide very targeted methods to improve the consistency of data , This will be a more effective way to get high-performance systems .
for example , If you have 10,000 A picture , Each of them 30 A group of pictures , this 30 The marks on this picture are inconsistent . One of the things we need to do is build tools , Can draw your attention to these inconsistencies . then , You can very quickly retag these images , Make it more consistent , In this way, the performance can be improved .
IEEE: You think if you can better design the data before training , Can this focus on high-quality data help solve the problem of data set deviation ?
Wu enda : Is likely to . Many researchers have pointed out that , Biased data is one of the many factors that lead to the deviation of the system . Actually , There has also been a lot of effort in designing data .NeurIPS At the Seminar ,Olga Russakovsky Made a great speech on this issue . I also like Mary Gray Speech at the meeting , It says “ Data centric AI” It's part of the solution , But not the whole solution . image Datasheets for Datasets Such new tools seem to be an important part of it .
“ Data centric AI” One of the powerful tools given to us is : The ability to engineer a single subset of data . Imagine , A trained machine learning system performs well on most data sets , But there is only a deviation on a subset of the data . Now , If you want to improve the performance of this subset , And change the whole neural network architecture , It's quite difficult . however , If only a subset of data can be designed , Then it can be more targeted to solve this problem .
IEEE: The data you said engineering Specifically, what does it mean ?
Wu enda : In the field of artificial intelligence , Data cleaning is important , But the way of data cleaning often needs to be solved manually . In computer vision , Someone might pass Jupyter notebook Visualize the image , To find and fix problems .
But I'm interested in tools that can handle large data sets . Even when the marking is noisy , These tools can also quickly and effectively draw your attention to a single subset of data , Or quickly direct your attention to 100 One of the groups , It would be more helpful to collect more data there . Collecting more data is often helpful , But if all the work needs to collect a lot of data , It can be very expensive .
for example , I once found , When there is car noise in the background , A speech recognition system will perform poorly . Understand this , I can collect more data against the background of car noise . Instead of collecting more data for all work , That would be very expensive and time-consuming .
IEEE: Would using synthetic data be a good solution ?
Wu enda : I think synthetic data is “ Data centric AI” An important tool in the toolbox . stay NeurIPS At the Seminar ,Anima Anandkumar Made a wonderful speech on synthetic data . I think the important use of synthetic data , It is not only reflected in the addition of learning algorithm data set in preprocessing . I hope to see more tools , Let developers use synthetic data generation to become part of the closed loop of machine learning iterative development .
IEEE: Do you mean that synthetic data allows you to try the model on more data sets ?
Wu enda : Is not the case, . For example , There are many different types of defects on smartphones , If you want to detect defects in the smartphone shell , That could be a scratch 、 Dent 、 Pit mark 、 Material discoloration or other types of defects . If you train the model , Then through error analysis, it is found that it performs very well on the whole , But it did badly in the pit marks , Then the generation of synthetic data can enable you to solve this problem more specifically . You can generate more data only for the pit category .
IEEE: Can you give an example to illustrate ? If a company finds Landing AI, They said they had a visual problem , How will you convince them ? What kind of solution will you give ?
Wu enda : Synthetic data generation is a very powerful tool , But I usually try many simpler tools first . For example, using data enhancement to improve label consistency , Or just ask the manufacturer to collect more data .
When customers find us , We usually talk about their testing problems first , And look at some images , To verify whether the problem is feasible in computer vision . If possible , We will ask them to upload the data to LandingLens platform . We usually base on “ Data centric AI” Ways to give them advice , And help them mark the data .
Landing AI One of the focuses of attention is to let manufacturing enterprises do machine learning by themselves . A lot of software is for our convenience . Through the development iteration of machine learning , We provide customers with how to train models on the platform , And how to improve the data labeling problem to improve the performance of the model . Our training and software will always play a role in this process , Until the trained model is deployed to the edge equipment of the factory .
IEEE: How do you respond to changing needs ? If the product changes or the lighting conditions of the factory change , In this case , Can the model adapt ?
Wu enda : This varies from manufacturer to manufacturer . In many cases, there are data offsets , But some manufacturers are already running on the same production line 20 year , Little has changed , So in the future 5 They don't expect change during the year , When the environment is stable, things become easier . For other manufacturers , We will also provide tools to mark when there is a big data offset problem . I have found that it enables manufacturing customers to independently correct data 、 It's really important to retrain and update the model . For example, it's early morning in the United States 3 spot , Once there is a change , I hope they can adjust their learning algorithm immediately , To maintain operations .
In the consumer software Internet , We can train a few machine learning models to 10 100 million user services . And in manufacturing , You may have 10,000 Customized by the manufacturer 10,000 Artificial intelligence model . The challenge is ,Landing AI I don't hire 10,000 In the case of a machine learning expert , How to do this ?
IEEE: So in order to improve the quality , Users must be authorized to conduct model training by themselves ?
Wu enda : Yes , Absolutely right ! This is an industry wide AI problem , Not just in manufacturing . For example, in the medical field , The format of EMR in each hospital is slightly different , How to train and customize your AI Model ? Expect every hospital to IT It is unrealistic for people to reinvent neural network architecture . therefore , Tools must be built , By providing users with tools to design data and express their domain knowledge , So that they can build their own models .
IEEE: Is there anything else you need readers to know ?
Wu enda : Over the past decade , The biggest shift in AI is deep learning , And the next ten years , I think we'll move to data centric . With the maturity of neural network architecture , For many practical applications , Bottlenecks will exist in “ How to get 、 Data needed for development ”. Data centric AI Great energy and potential in the community , I hope more researchers can join !

Dry goods learning , spot Fabulous Three even ↓
边栏推荐
猜你喜欢

Strengthen basic learning records

Strengthen basic learning records
Record an edu, SQL injection practice
Xray and burp linkage mining
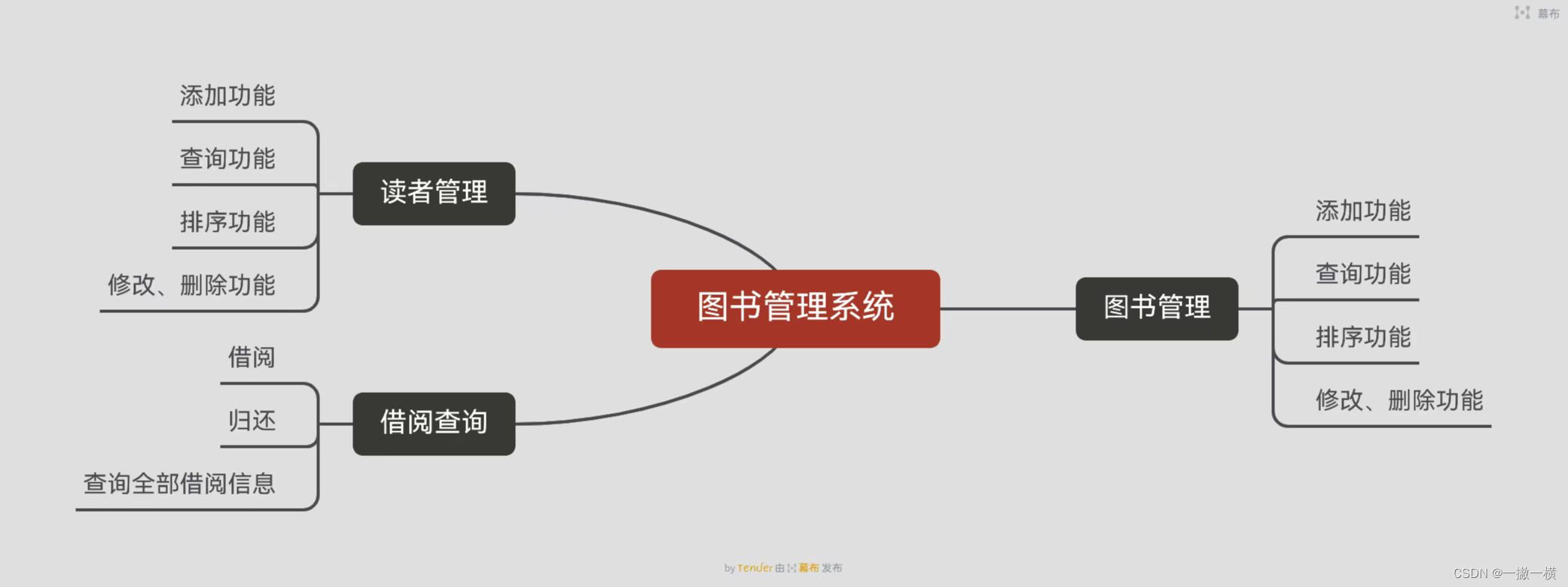
Library management system
攻防世界MISC练习区(SimpleRAR、base64stego、功夫再高也怕菜刀)
xray與burp聯動 挖掘
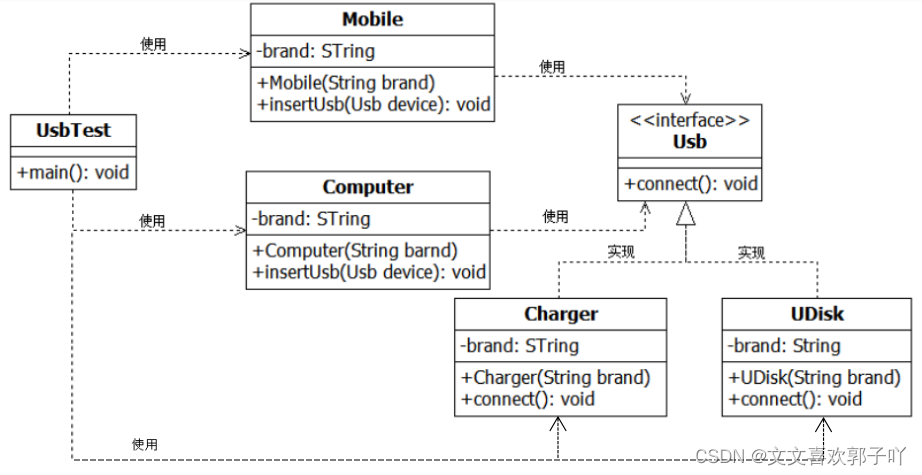
Experiment 6 inheritance and polymorphism

HackMyvm靶机系列(5)-warez
Harmonyos JS demo application development
随机推荐
记一次,修改密码逻辑漏洞实战
Poker game program - man machine confrontation
Detailed explanation of three ways of HTTP caching
Hcip -- MPLS experiment
Windows platform mongodb database installation
内网渗透之内网信息收集(一)
DVWA (5th week)
Tencent map circle
外网打点(信息收集)
强化学习基础记录
Hackmyvm target series (5) -warez
HackMyvm靶机系列(4)-vulny
Build domain environment (win)
HackMyvm靶机系列(3)-visions
Attack and defense world misc practice area (simplerar, base64stego, no matter how high your Kung Fu is, you are afraid of kitchen knives)
Load balancing ribbon of microservices
【头歌educoder数据表中数据的插入、修改和删除】
Circular queue (C language)
Web vulnerability - File Inclusion Vulnerability of file operation
实验五 类和对象