当前位置:网站首页>4. Apprentissage stratégique
4. Apprentissage stratégique
2022-07-08 01:14:00 【C - - G】
Policy Gradient with Baseline
Policy Gradient
- BaseLine


- Monte Carlo Approximation



- Choices of Baselines
Choice 1: b=0
**Choice 2:b is state-value **
- b = VΠ(St)




- Policy Network
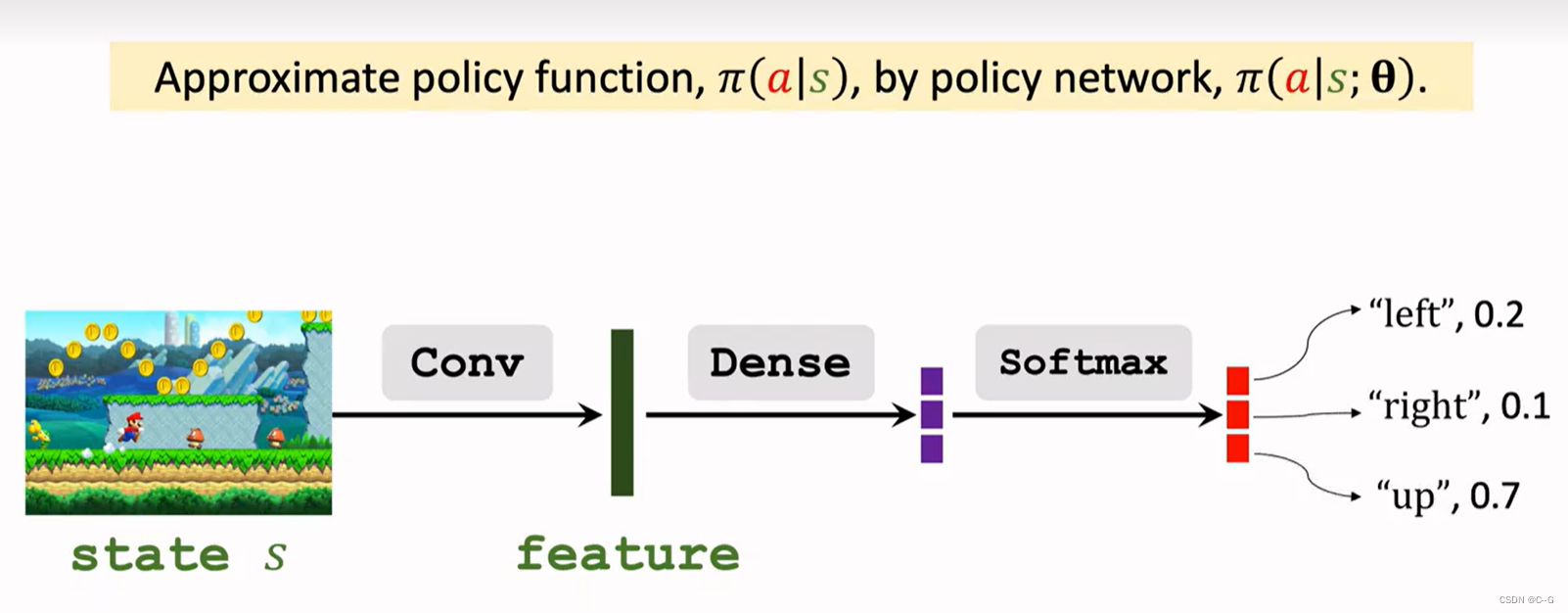
- Value Network
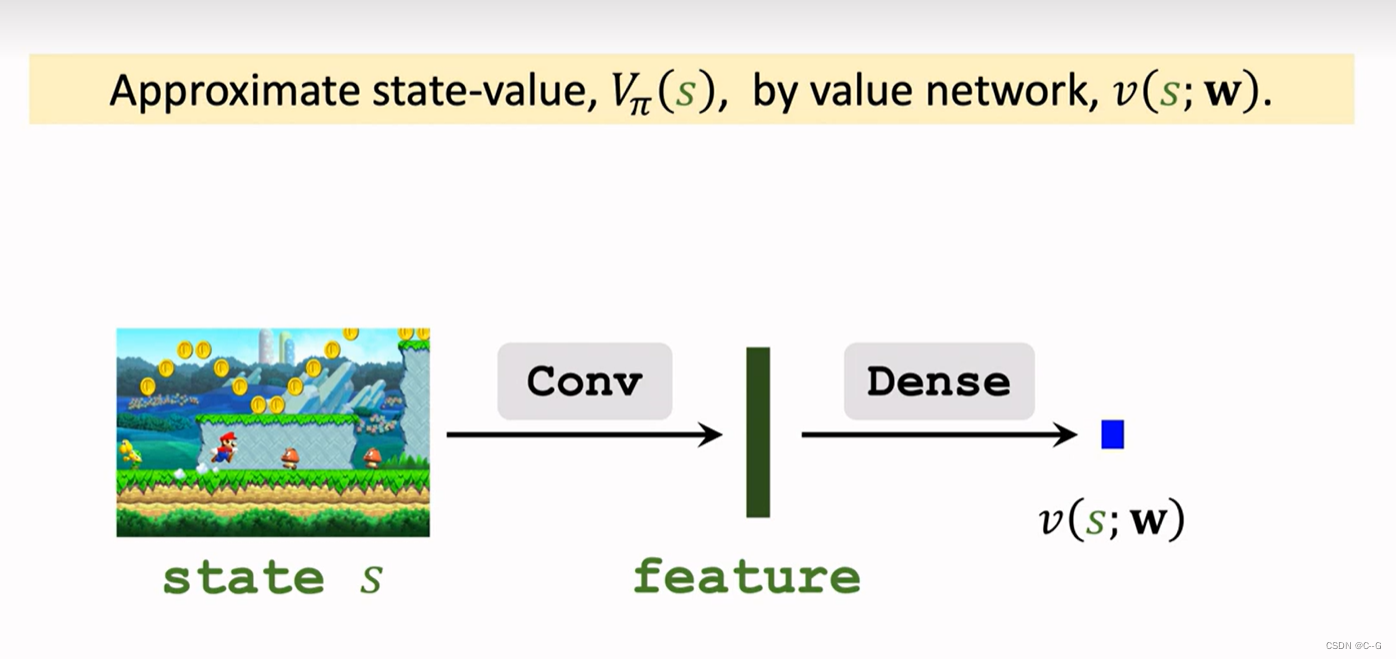
- Parameter Sharing
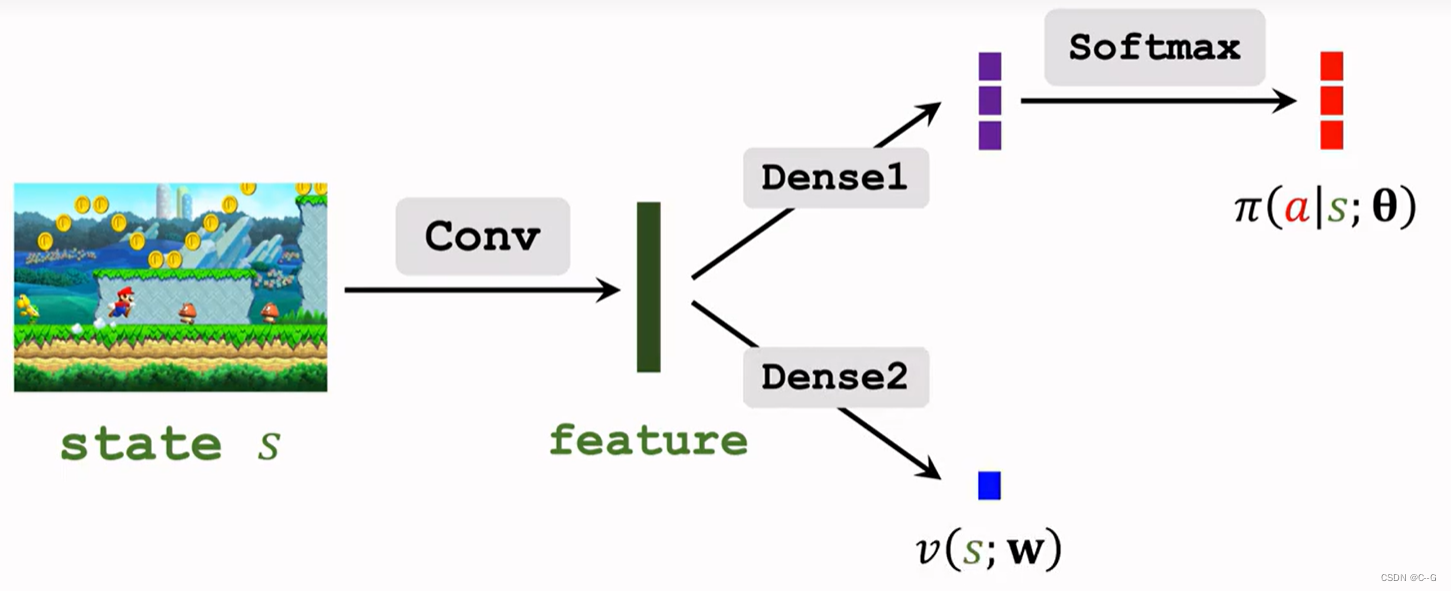
Reinforce with Baseline
- Updating the policy network

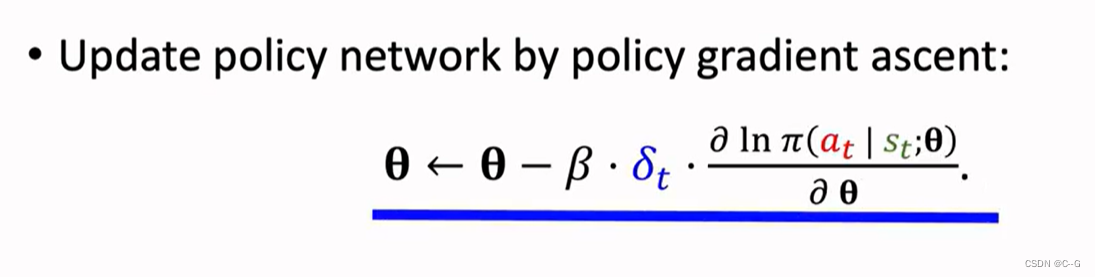

Advantage Actor-Critic(A2C)

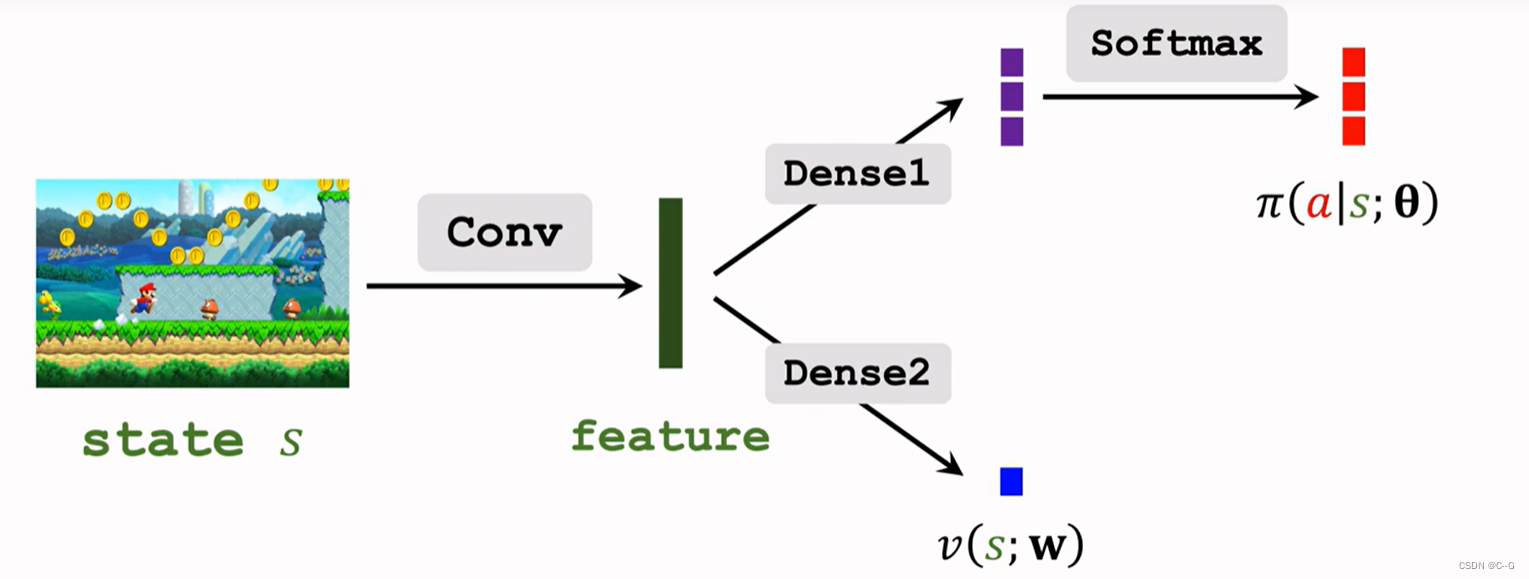

Reinforce versus A2C
La structure du réseau est presque identique entre les deux , Les réseaux de valeur sont différents 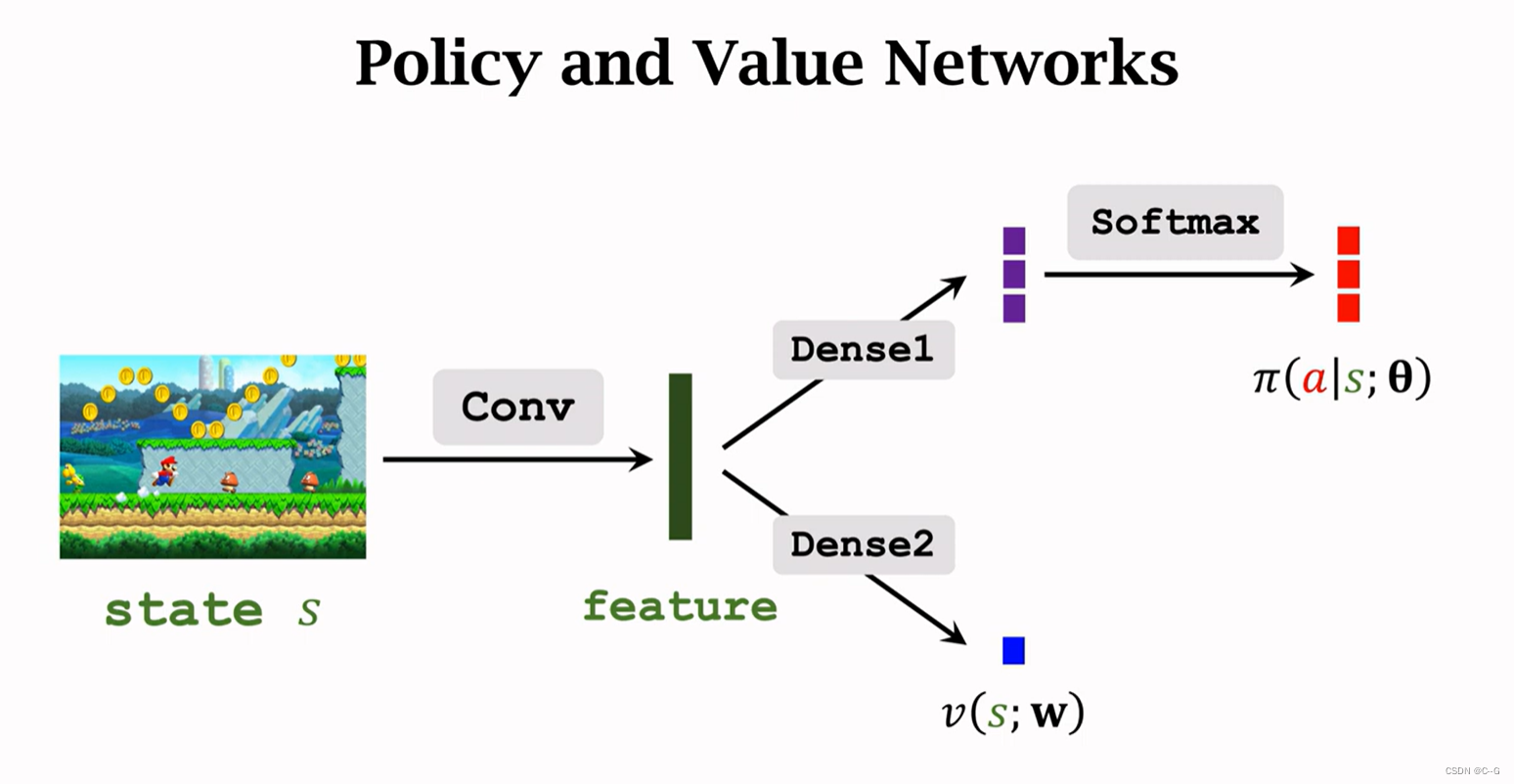
A2C with Multi-Step TD Target
one tep

Multi step
Reinforce with Baseline

versus


边栏推荐
- Recommend a document management tool mendely Reference Manager
- Study notes of single chip microcomputer and embedded system
- 2022-07-07: the original array is a monotonic array with numbers greater than 0 and less than or equal to K. there may be equal numbers in it, and the overall trend is increasing. However, the number
- Understanding of sidelobe cancellation
- 12.RNN应用于手写数字识别
- Introduction to paddle - using lenet to realize image classification method II in MNIST
- Design method and application of ag9311maq and ag9311mcq in USB type-C docking station or converter
- FOFA-攻防挑战记录
- Su embedded training - Day8
- Chapter 5 neural network
猜你喜欢
![[deep learning] AI one click to change the sky](/img/74/f2e854b9f24129bcd9376733c2369f.png)
[deep learning] AI one click to change the sky
10. CNN applied to handwritten digit recognition
7.正则化应用
Taiwan Xinchuang sss1700 latest Chinese specification | sss1700 latest Chinese specification | sss1700datasheet Chinese explanation
General configuration tooltip
Complete model verification (test, demo) routine

13. Enregistrement et chargement des modèles
FOFA-攻防挑战记录
AI遮天传 ML-回归分析入门
9.卷积神经网络介绍
随机推荐
【深度学习】AI一键换天
Ag9310 for type-C docking station scheme circuit design method | ag9310 for type-C audio and video converter scheme circuit design reference
String usage in C #
Common configurations in rectangular coordinate system
STL--String类的常用功能复写
Chapter 16 intensive learning
New library online | information data of Chinese journalists
14.绘制网络模型结构
Ag7120 and ag7220 explain the driving scheme of HDMI signal extension amplifier | ag7120 and ag7220 design HDMI signal extension amplifier circuit reference
STL -- common function replication of string class
Kuntai ch7511b scheme design | ch7511b design EDP to LVDS data | pin to pin replaces ch7511b circuit design
13.模型的保存和载入
Chapter improvement of clock -- multi-purpose signal modulation generation system based on ambient optical signal detection and custom signal rules
NTT template for Tourism
利用GPU训练网络模型
串口接收一包数据
1. Linear regression
[go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation
AI遮天传 ML-回归分析入门
Parade ps8625 | replace ps8625 | EDP to LVDS screen adapter or screen drive board